List to DataFrame in pyspark
20,414
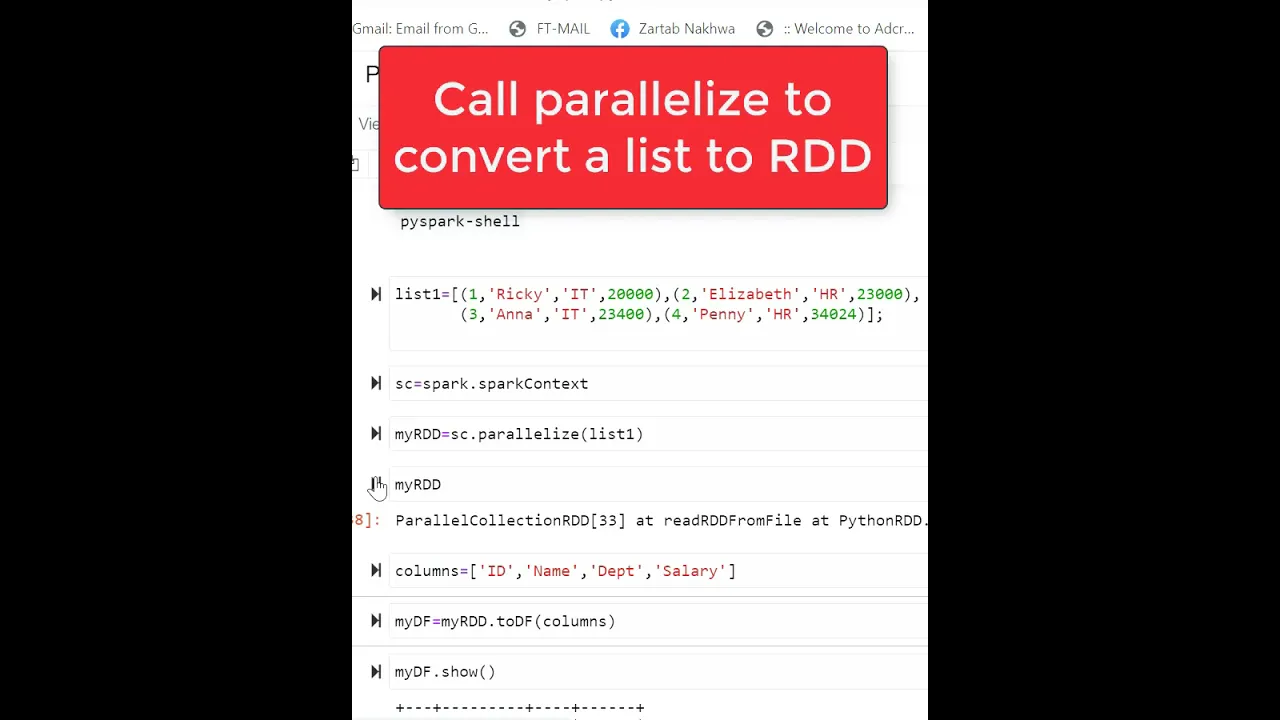
You can convert the list to a list of Row objects, then use spark.createDataFrame which will infer the schema from your data:
from pyspark.sql import Row
R = Row('ID', 'words')
# use enumerate to add the ID column
spark.createDataFrame([R(i, x) for i, x in enumerate(my_data)]).show()
+---+--------------------+
| ID| words|
+---+--------------------+
| 0|[apple, ball, bal...|
| 1| [cat, camel, james]|
| 2| [none, focus, cake]|
+---+--------------------+
Related videos on Youtube
 00 : 27
00 : 27
Converting a Python List to DataFrame in Pyspark #pyspark #hadoop #python #bigdata #shorts
 07 : 29
07 : 29
Checking if a list of columns present in a DataFrame | Pyspark
 01 : 49 : 02
01 : 49 : 02
PySpark Tutorial
 02 : 14
02 : 14
Spark Converting Python List to Spark DataFrame| Spark | Pyspark | PySpark Tutorial | Pyspark course
 10 : 25
10 : 25
Pyspark Tutorial 4, Spark Actions List, #SparkActions,#Actions,Min,Max,Stdev,takeSample,collect,take
 03 : 08
03 : 08
Pandas List To DataFrame | pd.DataFrame(your_list)
 08 : 31
08 : 31
Conversion of Data Frames | Spark to Pandas & Pandas to Spark
Author by
user9226665
Updated on July 09, 2022Comments
-
user9226665 almost 2 years
Can someone tell me how to convert a list containing strings to a Dataframe in pyspark. I am using python 3.6 with spark 2.2.1. I am just started learning spark environment and my data looks like below
my_data =[['apple','ball','ballon'],['cat','camel','james'],['none','focus','cake']]Now, i want to create a Dataframe as follows
--------------------------------- |ID | words | --------------------------------- 1 | ['apple','ball','ballon'] | 2 | ['cat','camel','james'] |I even want to add ID column which is not associated in the data
-
user9226665 over 6 yearsThnq for your reply.. but i am getting following error when i perform the code Py4JJavaError: An error occurred while calling o40.describe. : org.apache.spark.SparkException: Job aborted due to stage failure: Task 1 in stage 2.0 failed 1 times, most recent failure: Lost task 1.0 in stage 2.0 (TID 3, localhost, executor driver): org.apache.spark.api.python.PythonException: Traceback (most recent call last): File "pyspark/worker.py", line 123, in main ("%d.%d" % sys.version_info[:2], version))
-
 Psidom over 6 yearsTry restart pyspark shell. The error doesn't seem to be related to the code.
Psidom over 6 yearsTry restart pyspark shell. The error doesn't seem to be related to the code. -
 Bala about 6 yearsIsn't Awesome. Exactly what I was searching for
Bala about 6 yearsIsn't Awesome. Exactly what I was searching for