mysql - How to save ñ
Solution 1
Go to your database administration with MySQL WorkBench for example, put the Engine to InnoDB and the collation to utf8-utf8_general_ci.
Solution 2
You state in your question that you require a ISO-8859-1 backend (latin1), and a Unicode (UTF-8) frontend. This setup is crazy, because the set on the frontend is much larger than that allowed in the database. The sanest thing would be using the same encoding through the software stack, but also using Unicode only for storage would make sense.
As you should know, a String is a human concept for a sequence of characters. In computer programs, a String is not that: it can be viewed as a sequence of characters, but it's really a pair data structure: a stream of bytes and an encoding.
Once you understand that passing a String is really passing bytes and a scheme, let's see who sends what:
- Browser to HTTP server (usually same encoding as the form page, so UTF-8. The scheme is specified via
Content-Type. If missing, the server will pick one based on its own strategy, for example default to ISO-8859-1 or a configuration parameter) - HTTP Server to Java program (it's Java to Java, so the encoding doesn't matter since we pass String objects)
- Java client to MySQL server (the Connector/J documentation is quite convoluted - it uses the
character_set_serversystem variable, possibly overridden by thecharacterEncodingconnection parameter)
To understand where the problem lies, first assure that the column is really stored as latin1:
SELECT character_set_name, collation_name
FROM information_schema.columns
WHERE table_schema = :DATABASE
AND table_name = :TABLE
AND column_name = :COLUMN;
Then write the Java string you get from the request to a log file:
logger.info(request.getParameter("word"));
And finally see what actually is in the column:
SELECT HEX(:column) FROM :table
At this point you'll have enough information to understand the problem. If it's really a question mark (and not a replacement character) likely it's MySQL trying to transcode a character from a larger set (let's say Unicode) to a narrower one which doesn't contain it. The strange thing here is that ñ belongs to both ISO-8859-1 (0xF1, decimal 241) and Unicode (U+00F1), so it'd seem like there's a third charset (maybe a codepage?) involved in the round trip.
More information may help (operating system, HTTP server, MySQL version)
Solution 3
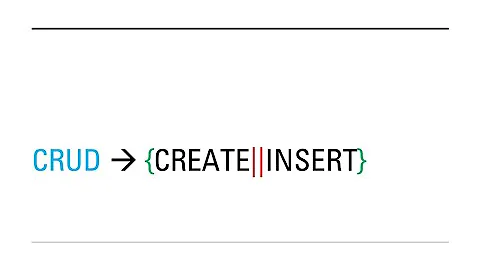
Change your db table content encoding to UTF-8
Here's the command for whole DB conversion
ALTER DATABASE db_name DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
And this is for single tables conversion
ALTER TABLE db_table CONVERT TO CHARACTER SET utf8 COLLATE utf8_general_ci;
Solution 4
change your table collate to utf8_spanish_ci
where ñ is not equal to n but if you want both characters to be equal use
utf8_general_ci instead
Solution 5
I try several combinations, but this works for me:
VARCHAR(255) BINARY CHARACTER SET utf8 COLLATE utf8_bin
When data retrieve in dbforge express, shows like: NIÑA
but in the application shows like: NIÑA
Related videos on Youtube
 10 : 50
10 : 50
 08 : 08
08 : 08
 02 : 17
02 : 17
 21 : 37
21 : 37
 02 : 41
02 : 41
 23 : 10
23 : 10
 11 : 05
11 : 05
 07 : 32
07 : 32
 09 : 28
09 : 28
 00 : 51
00 : 51
 28 : 59
28 : 59
Comments
-
 TheOnlyIdiot over 1 year
TheOnlyIdiot over 1 yearWhenever I try to save
ñit becomes?in the mysql database. After some few readings it is suggested that I have to change my jsp charset toUTF-8. For some reasons I have to stick toISO-8859-1. My database table encoding islatin1. How can I fix this? Please help.-
 swapnesh over 11 yearsChange your table encoding to UTF
swapnesh over 11 yearsChange your table encoding to UTF
-
-
andreszs almost 7 yearsHow comes that I can manually save ñ letter on a latin1 field, but after I convert it to binary the conversion to utf8_general_ci fails because of an "unknown string" error 1366? I can view it perfectly as ñ when saved in the table, but conversion to binary and then utf8 fails.
-
Crashman almost 6 yearsHi, did you resolve this issue, I have the same situation.
-
 Félix Adriyel Gagnon-Grenier over 5 yearsThat would not solve the problem when data is inserted again. Or do you propose to replace characters every time someone saves data to the database? That's untenable... It is, indeed, an encoding problem, see the other answers, and your own answer. You fixed it in your case by.. using the proper encoding.
Félix Adriyel Gagnon-Grenier over 5 yearsThat would not solve the problem when data is inserted again. Or do you propose to replace characters every time someone saves data to the database? That's untenable... It is, indeed, an encoding problem, see the other answers, and your own answer. You fixed it in your case by.. using the proper encoding. -
 Luis H Cabrejo over 5 yearsWell its solved permanently on goverment databases in south america. We have that issue and thats how we solved it here. using their UNICODE HTML Entity. We can insert, delete, update, and all functions of MySQL. No problem, the program does it transparently.
Luis H Cabrejo over 5 yearsWell its solved permanently on goverment databases in south america. We have that issue and thats how we solved it here. using their UNICODE HTML Entity. We can insert, delete, update, and all functions of MySQL. No problem, the program does it transparently. -
Félix Adriyel Gagnon-Grenier over 5 yearsOh, have no worries, I've seen people use HTML entities instead of fixing encoding plenty of time. It can probably even work, for a while. But then someone comes with another special character and then what, you redo all this with the new special character? Add more exceptions everywhere to account for all edge cases? That's what I mean by "untenable"; it's not a long term viable solution, it requires maintenance. Fixing the correct encoding, would solve the problem, without the need to fix it again every now and then.
-
Luis H Cabrejo over 5 yearsI dont create the exceptions, the program does it automatically with our limited set of funki characters. they are not many, á, é, í, ó, ú their capitals, ñ and Ñ are the problem ones. Very seldom dieresis are used ü, Ü. Thats all translations needed for our last names database. :)