Schema evolution in parquet format
Solution 1
Schema evolution can be (very) expensive.
In order to figure out schema, you basically have to read all of your parquet files and reconcile/merge their schemas during reading time which can be expensive depending on how many files or/and how many columns in there in the dataset.
Thus, since Spark 1.5, they switched off schema merging by default. You can always switch it back on).
Since schema merging is a relatively expensive operation, and is not a necessity in most cases, we turned it off by default starting from 1.5.0.
Without schema evolution, you can read schema from one parquet file, and while reading rest of files assume it stays the same.
Parquet schema evolution is implementation-dependent.
Hive for example has a knob parquet.column.index.access=false
that you could set to map schema by column names rather than by column index.
Then you could delete columns too, not just add.
As I said above, it is implementation-dependent, for example, Impala would not read such parquet tables correctly (fixed in recent Impala 2.6 release) [Reference].
Apache Spark, as of version 2.0.2, seems still only support adding columns: [Reference]
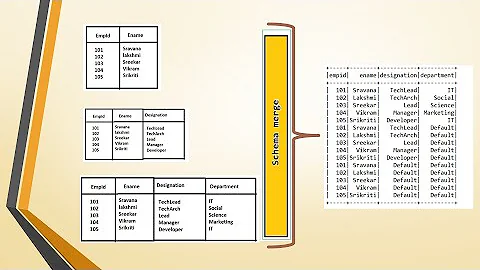
Users can start with a simple schema, and gradually add more columns to the schema as needed. In this way, users may end up with multiple Parquet files with different but mutually compatible schemas. The Parquet data source is now able to automatically detect this case and merge schemas of all these files.
PS: What I have seen some folks do to have more agility on schema changes, is that they create a view on top of actual parquet tables that map two (or more ) different but compatible schemas to one common schema.
Let's say you have added one new field (registration_date) and dropped another column (last_login_date) in your new release, then this would look like:
CREATE VIEW datamart.unified_fact_vw
AS
SELECT f1..., NULL as registration_date
FROM datamart.unified_fact_schema1 f1
UNION ALL
SELECT f2..., NULL as last_login_date
FROM datamart.unified_fact_schema2 f2
;
You got the idea. Nice thing it would work the same across all sql on Hadoop dialects (like I mentioned above Hive, Impala and Spark), and still have all the benefits of Parquet tables (columnar storage, predicate push-down etc).
P.P.S: adding some information regarding common_metadata summary files that Spark can create to make this answer more complete.
Have a look at SPARK-15719
Parquet summary files are not particular useful nowadays since
- when schema merging is disabled, we assume
schema of all Parquet part-files are identical,
thus we can read the footer from any part-files.
- when schema merging is enabled, we need to read footers
of all files anyway to do the merge.
On the other hand, writing summary files can be expensive,
because footers of all part-files must be read and merged.
This is particularly costly when appending a small dataset
to a large existing Parquet dataset.
So some points are against enabling common_metadata :
When a directory consists of Parquet files with a mixture of different schemas, _common_metadata allows readers to figure out a sensible schema for the whole directory without reading the schema of each individual file. Since Hive and Impala can access an SQL schema for said files from the Hive metastore, they can immediately start processing the individual files and match each of them against the SQL schema upon reading instead of exploring their common schema beforehand. This makes the common metadata feature unnecessary for Hive and Impala.
Even though Spark processes Parquet files without an SQL schema (unless using SparkSQL) and therefore in theory could benefit from _common_metadata, this feature was still deemed not to be useful and consequently got disabled by default in SPARK-15719.
Even if this feature were useful for querying, it is still a burden during writing. The metadata has to be maintained, which is not only slow, but also prone to racing conditions and other concurrency issues, suffers from the lack of atomicity guarantees, and easily leads to data correctness issues due to stale or inconsistent metadata.
The feature is undocumented and seems to be considered as deprecated (only "seems to be" because it never seems to have been supported officially at all in the first place, and a non-supported feature can not be deprecated either).
From one of Cloudera engineers: "I don't know whether the behavior has changed on the read side to avoid looking at each footer if the
common_metadatafile is present. But regardless, writing that file in the first place is a HUGE bottleneck, and has caused a lot of problems for our customers. I'd really strongly recommend they don't bother with trying to generate that metadata file.""_common_metadata" and "_metadata" files are Spark specific and are not written by Impala and Hive for example, and perhaps other engines.
Summary metadata files in Spark may still have its use cases though - when there are no concurrency and other issues described above - for example, some streaming use cases - I guess that's why this feature wasn't completely removed from Spark.
Solution 2
In addition to the above answer, other option is to set
"spark.hadoop.parquet.enable.summary-metadata" to "true"
What it does: it creates summary files with the schema when you write files. You will see summary files with '_metadata' and '_common_metadata' postfixes after saving. The _common_metadata is the compressed schema which is read everytime you read the parquet file. This makes read very fast as you have already have the schema. Spark looks for these schema files, if present, to get the schema.
Note that this makes writes very slow as Spark has to merge the schema of all files and create these schema file.
We had a similar situation where the parquet schema changed. What we did is set the above config to true for sometime after schema change so that the schema files are generated and then set it back to false. We had to compromise on slow writes for some time but after the schema files were generated, setting it to false served the purpose. And with a bonus of reading the files faster.
Related videos on Youtube
 08 : 45
08 : 45
 14 : 43
14 : 43
 18 : 54
18 : 54
 40 : 45
40 : 45
 24 : 38
24 : 38
 04 : 29
04 : 29
 07 : 41
07 : 41
 08 : 02
08 : 02
 28 : 37
28 : 37
 13 : 51
13 : 51
 01 : 45 : 52
01 : 45 : 52
 23 : 41
23 : 41
ToBeSparkShark
Updated on July 09, 2022Comments
-
ToBeSparkShark almost 2 years
Currently we are using Avro data format in production. Out of several good points using Avro, we know that it is good in schema evolution.
Now we are evaluating Parquet format because of its efficiency while reading random columns. So before moving forward our concern is still schema evolution.
Does anyone know if schema evolution is possible in parquet, if yes How is it possible, if no then Why not.
Some resources claim that it is possible but it can only add columns at end.
What does this mean?
-
teabot about 5 yearsThis suggests that 1) Parquet does not intrinsically support schema evolution, and that it is up to the file reader to make sense of the sets of schemas it finds embedded in a set of files? 2) I also presume there is not an external schema file, such as one finds in Avro (
avsc,avdletc.) ? -
akashdeep almost 5 yearsIf I've integer column and later on it got converted to float. How will I accommodate this schema change
-
 Tagar over 4 years@teabot I updated answer with
Tagar over 4 years@teabot I updated answer withsummary-metadatafiles. -
Tagar over 4 years@akashdeep
floatis a "common" datatype that can be used to store both integers and floats. Cast older table's integers tofloatunder same name as in the second table, and leave 2nd tables floats as is.. you got the idea.