What is the best way to partition large tables in SQL Server?
Solution 1
I don't think that you are really going to gain anything by partitioning the table across multiple databases in a single server. All you have essentially done there is increased the overhead in working with the "table" in the first place by having several instances (i.e. open in two different DBs) of it under a single SQL Server instance.
How large of a dataset do you have? I have a client with a 6 million row table in SQL Server that contains 2 years worth of sales data. They use it transactionally and for reporting without any noticiable speed problems.
Tuning the indexes and choosing the correct clustered index is crucial to performance of course.
If your dataset is really large and you are looking to partition, you will get more bang for your buck partitioning the table across physical servers.
Solution 2
Partitioning is not something to be undertaken lightly as there can be many subtle performance implications.
My first question is are you referring simply to placing larger table objects in separate filegroups (on separate spindles) or are you referring to data partitioning inside of a table object?
I suspect that the situation described is an attempt to have the physical storage of certain large tables on different spindles from the rest of the tables. In this case, adding the extra overhead of separate databases, losing any ability to enforce referential integrity across databases, and the security implications of enabling cross-database ownership chaining does not provide any benefit over using multiple filegroups within a single database. If, as is quite possible, the separate databases you refer to in your question are not even stored on separate spindles but are all stored on the same spindle then you negate even the slight performance benefit you could have gained by physically separating your disk activity and have received absolutely no benefit.
I would suggest instead of using additional databases to hold large tables you look into the Filegroup topic in SQL Server Books Online or for a quick review see this article:
If you are interested in data partitioning (including partitioning into multiple file groups) then I recommend reading articles by Kimberly Tripp, who gave an excellent presentation at the time SQL Server 2005 came out about the improvements available there. A good place to start is this whitepaper
Solution 3
Which version of SQL Server are you using? SQL Server 2005 has partitioned tables, but in 2000 (or 7.0) you needed to use partition views.
Also, what was the reasoning for putting the table partitions in a separate database?
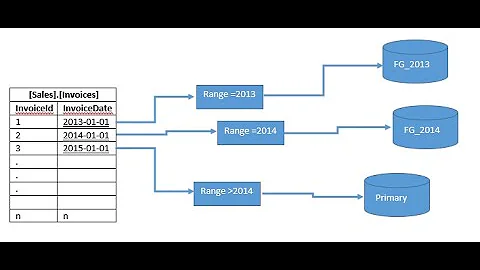
When I've had to partition tables in the past (pre-2005), it's usually by a date column or something similar, with a view over the various partitions. Books Online has a section that talks about how to do this and all of the rules around it. You need to follow the rules to make it work how it's supposed to work.
The key thing to remember is that your partitioning column must be part of the primary key and you want to try to always use that column in any access against the table so that the optimizer can ignore partitions that shouldn't be affected by the query.
Look up "partitioned table" in MSDN and you should be able to find a more complete tutorial for SQL Server 2005 partitioned tables as well as advice on how to set them up for maximum performance.
Solution 4
Are you asking about best practices in terms of database design, or convincing your lead to change his mind? :)
In terms of design... Back in the goode olde days, vertical partitioning was sometimes needed to work around database engine limitations, where the number of columns in a table was a hard limit, like 255 columns. These days the main benefits are purely for performance: putting rarely used columns, or blobs on a separate disk array. But if you're regularly pulling things from both tables it will likely be a loss. It sounds like your lead is suffering from a case of premature optimisation.
In terms of telling your lead is wrong... that requires diplomacy. If he's aware of mutterings of discontent in terms of performance, a benchmark is probably the best way to show the difference.
Create a new physical table somewhere with 'create table t1 as select * from view1' and then run some lengthy batch with the vertically partitioned table and your new table. If it's as bad as you say, the difference should be evident.
But this too may be premature optimisation. Find out what the end-users think of the performance. If the performance is good enough, for some definition of good, then don't fix what ain't broke.
Solution 5
There is a definite benefit for table partitioning (regardless whether it's on same or different filegroups /disks). If the partition column is correctly selected, you'll realize that your queries will hit only the required partition. So imagine if you have 100 million records (I've partitioned tables much bigger than that - about 20+ Billion rows) and if for the most part, more than 70% of your data access is only a certain category or timeline or type of data then it helps to keep the most accessed data in a separate partition. Plus you can align the partition with separate file groups with various type of disks (SATA, Fiber channel, SSDs) so that the most accessed/busy data are on the fastest storage and the least/rarely accessed are virtually on slower disks.
Although, in SQL Server there's limited partitioning ability, unlike Oracle. You can choose only one column for partitioning (even in SQL 2008). So you've to choose a column wisely where that column also is part of most of your frequent queries. For the most part, people find it easy to choose to partition by a date column. However although it seems logical to partition that way, if your queries do not have that column as part of the condition, you won't be gaining sufficient benefits from partitioning (in other words, your query will hit all the partition regardless).
It's much easier to partition for data warehouse/data mining type databases than OLTP as most DW database queries are limited by time period.
That's why these days due to the volume of data being handled by databases, it's wise to design the application in such a way that ever query is limited by some broader group such as time, geographical location or such so that when such columns are chosen for partitioning you'll gain maximum benefits.
Related videos on Youtube
 05 : 49
05 : 49
 42 : 49
42 : 49
 14 : 17
14 : 17
 01 : 05 : 03
01 : 05 : 03
 03 : 06
03 : 06
 15 : 11
15 : 11
 28 : 08
28 : 08
Comments
-
 010 about 4 years
010 about 4 yearsIn a recent project the "lead" developer designed a database schema where "larger" tables would be split across two separate databases with a view on the main database which would union the two separate database-tables together. The main database is what the application was driven off of so these tables looked and felt like ordinary tables (except some quirky things around updating). This seemed like a HUGE performance problem. We do see problems with performance around these tables but nothing to make him change his mind about his design. Just wondering what is the best way to do this, or if it is even worth doing?
-
Dave DuPlantis over 15 yearsSQLTeam.com also has had recent posts about partitioning and automating maintenance: weblogs.sqlteam.com.
-
Tomek Szpakowicz over 14 yearsI can't see how partitioning table by batch field would cause less IO. If batch is a part of proper indexes, it will reduce number of rows that need to be read regardless of partitioning. Now IO is a function of data rows that need to be read. How does partitioning improve anything?
-
Tomek Szpakowicz over 14 yearsHow partitioning table between several physical devices is better than configuring filegroup that spans those devices, as Joe Kuemerle proposes? I understand that in some very specific situations it can be more efficient to set it up manually. But isn't it a very exceptional situation? I guess usually it's cheaper to buy a bigger RAID than have your developers and DBAs spend lots of time moving tables around.