Can someone clarify the difference between Quicksort and Randomized Quicksort?
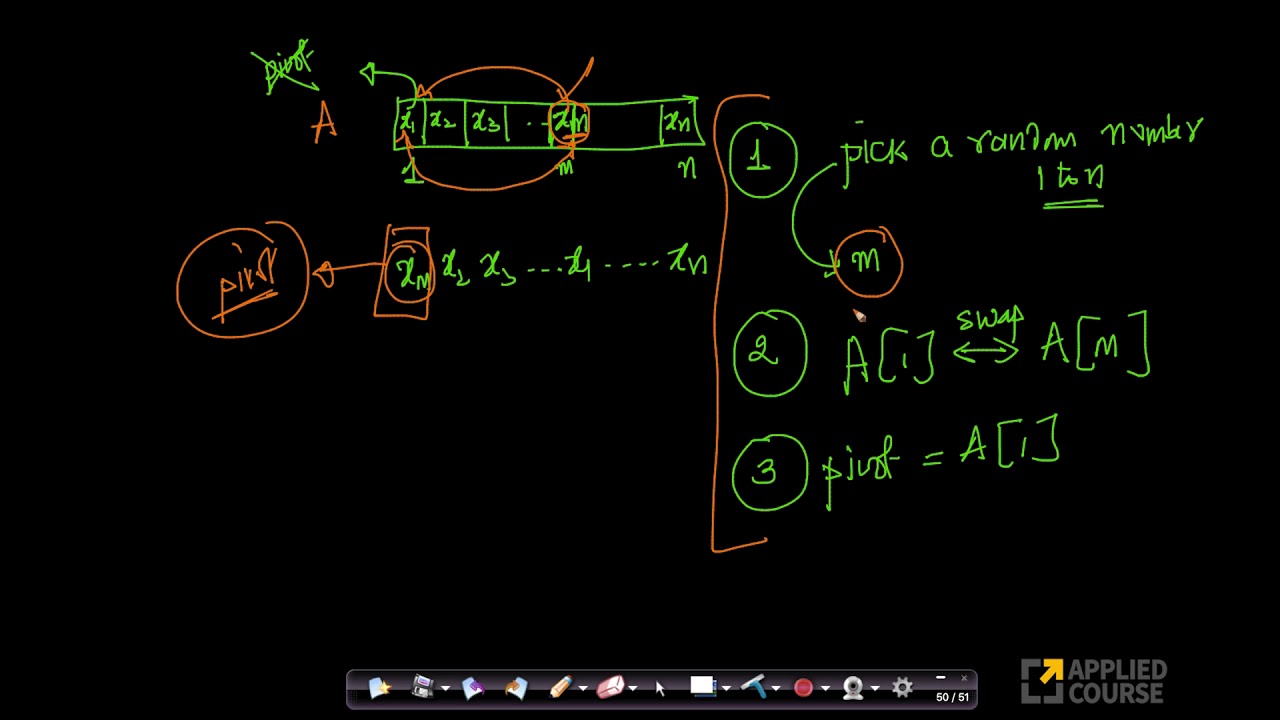
I think you may be mixing up the concepts of arbitrary and random. It's arbitrary to pick the first element of the array - you could pick any element you'd like and it would work equally well - but it's not random. A random choice is one that can't be predicted in advance. An arbitrary choice is one that can be.
Let's imagine that you're using quicksort on the sorted sequence 1, 2, 3, 4, 5, 6, ..., n. If you choose the first element as a pivot, then you'll choose 1 as the pivot. All n - 1 other elements then go to the right and nothing goes to the left, and you'll recursively quicksort 2, 3, 4, 5, ..., n.
When you quicksort that range, you'll choose 2 as the pivot. Partitioning the elements then puts nothing on the left and the numbers 3, 4, 5, 6, ..., n on the right, so you'll recursively quicksort 3, 4, 5, 6, ..., n.
More generally, after k steps, you'll choose the number k as a pivot, put the numbers k+1, k+2, ..., n on the right, then recursively quicksort them.
The total work done here ends up being Θ(n2), since on the first pass (to partition 2, 3, ..., n around 1) you have to look at n-1 elements, on the second pass (to partition 3, 4, 5, ..., n around 2), you have to look at n-2 elements, etc. This means that the work done is (n-1)+(n-2)+ ... +1 = Θ(n2), quite inefficient!
Now, contrast this with randomized quicksort. In randomized quicksort, you truly choose a random element as your pivot at each step. This means that while you technically could choose the same pivots as in the deterministic case, it's very unlikely (the probability would be roughly 22 - n, which is quite low) that this will happen and trigger the worst-case behavior. You're more likely to choose pivots closer to the center of the array, and when that happens the recursion branches more evenly and thus terminates a lot faster.
The advantage of randomized quicksort is that there's no one input that will always cause it to run in time Θ(n log n) and the runtime is expected to be O(n log n). Deterministic quicksort algorithms usually have the drawback that either (1) they run in worst-case time O(n log n), but with a high constant factor, or (2) they run in worst-case time O(n2) and the sort of input that triggers this case is deterministic.
Related videos on Youtube
 04 : 24
04 : 24
 01 : 06 : 36
01 : 06 : 36
 06 : 30
06 : 30
 04 : 22
04 : 22
 39 : 30
39 : 30
 07 : 58
07 : 58
 22 : 45
22 : 45
 13 : 43
13 : 43
driftdrift
Updated on October 31, 2022Comments
-
 driftdrift about 1 year
driftdrift about 1 yearHow is it different if I select a randomized pivot versus just selecting the first pivot in an unordered set/list?
If the set is unordered, isnt selecting the first value in the set, random in itself? So essentially, I am trying to understand how/if randomizing promises a better worst case runtime.
-
 Paul Hankin almost 7 yearsIt doesn't provide a better worst case, but unlike the non-random version there is no one input that provokes the worst case. It may be helpful to think of the input as being provided by an evil attacker who knows your code and who wants you to spend as much time as possible sorting the input.
Paul Hankin almost 7 yearsIt doesn't provide a better worst case, but unlike the non-random version there is no one input that provokes the worst case. It may be helpful to think of the input as being provided by an evil attacker who knows your code and who wants you to spend as much time as possible sorting the input.
-
-
driftdrift almost 7 yearsthanks for the explanation. I do see the improvement of the algorithm and Most of it is clear except the last part. If the "randomly chosen pivot" chooses the first element each time, and the input array is sorted already [1,2,3,4,5], I don't see how it can guarntee a worst case O(nlogn).
-
 Gassa almost 7 years@driftdrift A randomized quicksort is expected O(n log n), not worst-case O(n log n). "Expected" means "on average". One can prove that, for large enough inputs, the probability of quadratic behavior becomes vanishingly small. So, in practice, the quadratic case does not happen, but theoretically, the probability is still non-zero.
Gassa almost 7 years@driftdrift A randomized quicksort is expected O(n log n), not worst-case O(n log n). "Expected" means "on average". One can prove that, for large enough inputs, the probability of quadratic behavior becomes vanishingly small. So, in practice, the quadratic case does not happen, but theoretically, the probability is still non-zero.