Difference between Breadth First Search, and Iterative deepening
Solution 1
From What I understand iterative deepening does DFS down to depth 1 then does DFS down to depth of 2 ... down to depth n , and so on till it finds no more levels
for example I think that tree would be read
read visited depth
A A 1
ABC ABAC 2
ABDCEF ABDBACECF 3
I believe its pretty much doing a separate DFS with depth limit for each level and throwing away the memory.
Solution 2
From my understanding of the algorithm, IDDFS (iterative-deepening depth-first search) is simply a depth-first search performed multiple times, deepening the level of nodes searched at each iteration. Therefore, the memory requirements are the same as depth-first search because the maximum depth iteration is just the full depth-first search.
Therefore, for the example of the tree you gave, the first iteration would visit node A, the second iteration would visit nodes A, B, and C, and the third iteration would visit all of the nodes of the tree.
The reason it is implemented like this is so that, if the search has a time constraint, then the algorithm will at least have some idea of what a "good scoring" node is if it reaches the time-limit before doing a full traversal of the tree.
This is different than a breadth-first search because at each iteration, the nodes are visited just like they would be in a depth-first search, not like in a breadth-first search. Typically, IDDFS algorithms would probably store the "best scoring" node found from each iteration.
Solution 3
the memory usage is the the maximum number of nodes it saves at any point. not the number of nodes visited.
at any time IDFS needs to store only the nodes in the branch it is expanding.only the A and C if we are expanding C (in your e.g). BFS must save all the nodes of the depth it is searching. to see the effect take a tree with branching factor 8 rather than 2. to search to a depth of 3, BFS needs to store a massive 64 nodes. IDFS needs only 3.
Solution 4
In each iteration of Iterative-Deepening Search, we have a limit and we traverse the graph using the DFS approach, however, for each step of each iteration, we just need to keep track of only nodes inside the path from the root to depth d. That's the saving in memory.
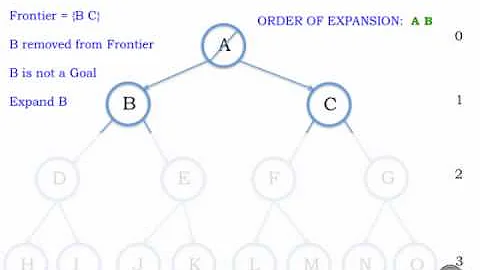
For example, look at the last row of the picture below. If we have used BFS, we had to keep track of all nodes up to depth 2. But because we are using DFS, we don't need to keep all of them in memory since either some nodes are already visited so we don't need them, or not visited yet so we will add it later. We just keep our path to the root (the gray path).

The picture is from Artificial Intelligence book by Peter Norvig and Stuart Russel
Related videos on Youtube
 10 : 59
10 : 59
 03 : 40
03 : 40
 07 : 15
07 : 15
 05 : 53
05 : 53
 06 : 14
06 : 14
![[PCTV] [AI] IDS - Tìm kiếm theo sâu dần (Iterative Deepening Search)](https://i.ytimg.com/vi/gzbVeUMKbC0/hq720.jpg?sqp=-oaymwEcCNAFEJQDSFXyq4qpAw4IARUAAIhCGAFwAcABBg==&rs=AOn4CLAJNPoiEgqKakc2T9oepSE8Bull8A) 11 : 33
11 : 33
 18 : 31
18 : 31
theraven
iOS developer for Itty Bitty Apps makers of Reveal, http://revealapp.com
Updated on July 09, 2022Comments
-
theraven almost 2 years
I understand BFS, and DFS, but for the life of me cannot figure out the difference between iterative deepening and BFS. Apparently Iterative deepening has the same memory usage as DFS, but I am unable to see how this is possible, as it just keeps expanding like BFS. If anyone can clarify that would be awesome.
tree to work on if required:
A / \ B C / / \ D E F -
Steven Oxley almost 14 yearsI agree with your analysis of how the algorithm works, but I believe "visit" means "operate on" in most algorithm books (and descriptions I've read online), which appears to be what you're using "read" to mean.
-
Roman A. Taycher almost 14 yearsI'm thinking in terms of a recursive implementation with read being where you actually get the value and visit being whats on top of the stack.
-
Steven Oxley almost 14 yearsYeah, I understand what you're meaning, but I think that "visit" is the term that is usually used to mean when you actually get the value (or do some sort of operation on the node).
-
Roman A. Taycher almost 14 yearsWhat do people usually use to refer to what I marked as read? and is there any popular alternative to using visited to get the value(it just sound wrong to me)?
-
 William Morrison almost 11 years+1, many people can explain the algorithm. No one was explaining why repeating work on iterative searches was necessary other than just to mention the obvious memory advantages.
William Morrison almost 11 years+1, many people can explain the algorithm. No one was explaining why repeating work on iterative searches was necessary other than just to mention the obvious memory advantages. -
Beright over 10 years@William Morrison IDDFS would not have any better idea than BFS what a "good scoring" node is, the memory advantage is the only advantage.
-
William Morrison over 10 years@Beright You're mistaken. Iterative deepening does have a better idea than BFS on which nodes score well as its evaluated nodes on previous passes. IDDFS can use this information to search higher scoring nodes first.
-
Beright about 10 years@William Morrison You're talking about training up a heuristic or evaluation function on the initial shallower searches to make better decisions using pruning or heuristic search techniques. BFS could also be run repeatedly with early cutoff to train a heuristic, in which case it could take the same shortcuts. IDDFS requiring you do the repeated work (regardless of whether you use it to train) is thus not an advantage.
-
William Morrison about 10 yearsAh I see. I was thinking IDDFS always used a heuristic. But IDDFS doesn't necessarily use a heuristic. And even if IDDFS has a heuristic, it offers no advantage over BFS with the same heuristic, except in terms of memory. You're right, my mistake.
-
 Mostafa Ghadimi about 4 yearsHi Iman, Does this prove that Iterative Deepening always expand (traverse) more nodes than BFS?
Mostafa Ghadimi about 4 yearsHi Iman, Does this prove that Iterative Deepening always expand (traverse) more nodes than BFS?