Does my hard-drive have bad sectors or not?
Your disk had some problems with reading data from the surface, but it seems that the disk dealt with it. I had similar situation:
Error 29 occurred at disk power-on lifetime: 18836 hours (784 days + 20 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
40 51 08 00 40 37 e6 Error: UNC 8 sectors at LBA = 0x06374000 = 104284160
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
c8 00 08 00 40 37 e6 08 03:39:32.447 READ DMA
c8 00 08 f8 3f 37 e6 08 03:39:32.447 READ DMA
c8 00 08 f0 3f 37 e6 08 03:39:32.447 READ DMA
c8 00 08 e8 3f 37 e6 08 03:39:32.447 READ DMA
c8 00 08 e0 3f 37 e6 08 03:39:32.447 READ DMA
And when I wanted to perform test, I got:
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 7 Short offline Completed: read failure 90% 18845 104284160
Ultimately, I managed to unblock the sectors, and after running the extended test, which scan the whole surface, I got the following result:
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 3 Extended offline Completed without error 00% 18858 -
If there were bad blocks, they could be observed in the table under:
5 Reallocated_Sector_Ct 0x0033 200 200 140 Pre-fail Always - 0
196 Reallocated_Event_Count 0x0032 200 200 000 Old_age Always - 0
197 Current_Pending_Sector 0x0032 200 200 000 Old_age Always - 0
In your case, there's no indication of bad sectors because the extended test was performed (11746 h) after the last error occurred (11706 h). So, you can sleep peacefully. :)
As I mentioned in comments, there's two types of badblocks. Here's short info about the difference between the two:
There are two types of bad sectors — often divided into “physical” and “logical” bad sectors or “hard” and “soft” bad sectors.
A physical — or hard — bad sector is a cluster of storage on the hard drive that’s physically damaged. The hard drive’s head may have touched that part of the hard drive and damaged it, some dust may have settled on that sector and ruined it, a solid-state drive’s flash memory cell may have worn out, or the hard drive may have had other defects or wear issues that caused the sector to become physically damaged. This type of sector cannot be repaired.
A logical — or soft — bad sector is a cluster of storage on the hard drive that appears to not be working properly. The operating system may have tried to read data on the hard drive from this sector and found that the error-correcting code (ECC) didn’t match the contents of the sector, which suggests that something is wrong. These may be marked as bad sectors, but can be repaired by overwriting the drive with zeros — or, in the old days, performing a low-level format. Windows’ Disk Check tool can also repair such bad sectors.
Related videos on Youtube
 09 : 24
09 : 24
 15 : 07
15 : 07
 08 : 02
08 : 02
 03 : 31
03 : 31
 08 : 20
08 : 20
landroni
Updated on September 18, 2022Comments
-
 landroni 9 months
landroni 9 monthsI got a new drive and I'm confused if
smartctldetects bad sectors or not. Both short and extended self-testscompleted without error. But theError LogindicatesUncorrectable error in datafor96 sectors.Here's the
smartctloutput:smartctl 5.41 2011-06-09 r3365 [i686-linux-3.2.0-52-generic] (local build) Copyright (C) 2002-11 by Bruce Allen, http://smartmontools.sourceforge.net === START OF INFORMATION SECTION === Model Family: Hitachi Deskstar T7K500 Device Model: Hitachi HDT725025VLA380 Serial Number: VFL104R73X993Z LU WWN Device Id: 5 000cca 316f723ca Firmware Version: V5DOA73A User Capacity: 250,059,350,016 bytes [250 GB] Sector Size: 512 bytes logical/physical Device is: In smartctl database [for details use: -P show] ATA Version is: 7 ATA Standard is: ATA/ATAPI-7 T13 1532D revision 1 Local Time is: Wed Feb 5 19:19:29 2014 UTC SMART support is: Available - device has SMART capability. SMART support is: Enabled === START OF READ SMART DATA SECTION === SMART overall-health self-assessment test result: PASSED General SMART Values: Offline data collection status: (0x80) Offline data collection activity was never started. Auto Offline Data Collection: Enabled. Self-test execution status: ( 0) The previous self-test routine completed without error or no self-test has ever been run. Total time to complete Offline data collection: ( 4949) seconds. Offline data collection capabilities: (0x5b) SMART execute Offline immediate. Auto Offline data collection on/off support. Suspend Offline collection upon new command. Offline surface scan supported. Self-test supported. No Conveyance Self-test supported. Selective Self-test supported. SMART capabilities: (0x0003) Saves SMART data before entering power-saving mode. Supports SMART auto save timer. Error logging capability: (0x01) Error logging supported. General Purpose Logging supported. Short self-test routine recommended polling time: ( 1) minutes. Extended self-test routine recommended polling time: ( 83) minutes. SCT capabilities: (0x003f) SCT Status supported. SCT Error Recovery Control supported. SCT Feature Control supported. SCT Data Table supported. SMART Attributes Data Structure revision number: 16 Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 1 Raw_Read_Error_Rate 0x000b 100 100 016 Pre-fail Always - 0 2 Throughput_Performance 0x0005 100 100 050 Pre-fail Offline - 0 3 Spin_Up_Time 0x0007 110 110 024 Pre-fail Always - 338 (Average 340) 4 Start_Stop_Count 0x0012 100 100 000 Old_age Always - 1838 5 Reallocated_Sector_Ct 0x0033 100 100 005 Pre-fail Always - 0 7 Seek_Error_Rate 0x000b 100 100 067 Pre-fail Always - 0 8 Seek_Time_Performance 0x0005 100 100 020 Pre-fail Offline - 0 9 Power_On_Hours 0x0012 099 099 000 Old_age Always - 11746 10 Spin_Retry_Count 0x0013 100 100 060 Pre-fail Always - 0 12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 1822 192 Power-Off_Retract_Count 0x0032 099 099 000 Old_age Always - 2103 193 Load_Cycle_Count 0x0012 099 099 000 Old_age Always - 2103 194 Temperature_Celsius 0x0002 162 162 000 Old_age Always - 37 (Min/Max 12/48) 196 Reallocated_Event_Count 0x0032 100 100 000 Old_age Always - 0 197 Current_Pending_Sector 0x0022 100 100 000 Old_age Always - 0 198 Offline_Uncorrectable 0x0008 100 100 000 Old_age Offline - 0 199 UDMA_CRC_Error_Count 0x000a 200 253 000 Old_age Always - 0 SMART Error Log Version: 1 ATA Error Count: 27 (device log contains only the most recent five errors) CR = Command Register [HEX] FR = Features Register [HEX] SC = Sector Count Register [HEX] SN = Sector Number Register [HEX] CL = Cylinder Low Register [HEX] CH = Cylinder High Register [HEX] DH = Device/Head Register [HEX] DC = Device Command Register [HEX] ER = Error register [HEX] ST = Status register [HEX] Powered_Up_Time is measured from power on, and printed as DDd+hh:mm:SS.sss where DD=days, hh=hours, mm=minutes, SS=sec, and sss=millisec. It "wraps" after 49.710 days. Error 27 occurred at disk power-on lifetime: 11706 hours (487 days + 18 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER ST SC SN CL CH DH -- -- -- -- -- -- -- 40 51 60 e4 33 e7 47 Error: UNC 96 sectors at LBA = 0x07e733e4 = 132592612 Commands leading to the command that caused the error were: CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name -- -- -- -- -- -- -- -- ---------------- -------------------- 25 03 80 c4 33 e7 40 00 02:28:22.700 READ DMA EXT 25 03 01 00 00 00 40 00 02:28:22.200 READ DMA EXT 25 03 01 00 00 00 40 00 02:28:22.200 READ DMA EXT 25 03 01 00 00 00 40 00 02:28:22.200 READ DMA EXT ef 03 46 c4 33 e7 00 00 02:28:22.200 SET FEATURES [Set transfer mode] Error 26 occurred at disk power-on lifetime: 11706 hours (487 days + 18 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER ST SC SN CL CH DH -- -- -- -- -- -- -- 40 51 60 e4 33 e7 47 Error: UNC 96 sectors at LBA = 0x07e733e4 = 132592612 Commands leading to the command that caused the error were: CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name -- -- -- -- -- -- -- -- ---------------- -------------------- 25 03 80 c4 33 e7 40 00 02:28:11.700 READ DMA EXT 25 03 01 00 00 00 40 00 02:28:11.200 READ DMA EXT 25 03 01 00 00 00 40 00 02:28:11.200 READ DMA EXT 25 03 01 00 00 00 40 00 02:28:11.200 READ DMA EXT ef 03 46 c4 33 e7 00 00 02:28:11.200 SET FEATURES [Set transfer mode] Error 25 occurred at disk power-on lifetime: 11706 hours (487 days + 18 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER ST SC SN CL CH DH -- -- -- -- -- -- -- 40 51 60 e4 33 e7 47 Error: UNC 96 sectors at LBA = 0x07e733e4 = 132592612 Commands leading to the command that caused the error were: CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name -- -- -- -- -- -- -- -- ---------------- -------------------- 25 03 80 c4 33 e7 40 00 02:28:00.700 READ DMA EXT 25 03 01 00 00 00 40 00 02:28:00.200 READ DMA EXT 25 03 01 00 00 00 40 00 02:28:00.200 READ DMA EXT 25 03 01 00 00 00 40 00 02:28:00.200 READ DMA EXT ef 03 46 c4 33 e7 00 00 02:28:00.200 SET FEATURES [Set transfer mode] Error 24 occurred at disk power-on lifetime: 11706 hours (487 days + 18 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER ST SC SN CL CH DH -- -- -- -- -- -- -- 40 51 60 e4 33 e7 47 Error: UNC 96 sectors at LBA = 0x07e733e4 = 132592612 Commands leading to the command that caused the error were: CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name -- -- -- -- -- -- -- -- ---------------- -------------------- 25 03 80 c4 33 e7 40 00 02:27:49.700 READ DMA EXT 25 03 01 00 00 00 40 00 02:27:49.200 READ DMA EXT 25 03 01 00 00 00 40 00 02:27:49.200 READ DMA EXT 25 03 01 00 00 00 40 00 02:27:49.200 READ DMA EXT ef 03 46 c4 33 e7 00 00 02:27:49.200 SET FEATURES [Set transfer mode] Error 23 occurred at disk power-on lifetime: 11706 hours (487 days + 18 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER ST SC SN CL CH DH -- -- -- -- -- -- -- 40 51 60 e4 33 e7 47 Error: UNC 96 sectors at LBA = 0x07e733e4 = 132592612 Commands leading to the command that caused the error were: CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name -- -- -- -- -- -- -- -- ---------------- -------------------- 25 03 80 c4 33 e7 40 00 02:27:38.900 READ DMA EXT 25 03 08 7c a8 3a 40 00 02:27:38.900 READ DMA EXT 35 03 08 7c a8 3a 40 00 02:27:38.900 WRITE DMA EXT 25 03 08 7c a8 3a 40 00 02:27:38.900 READ DMA EXT 25 03 08 a4 eb 94 40 00 02:27:38.900 READ DMA EXT SMART Self-test log structure revision number 1 Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error # 1 Extended offline Completed without error 00% 11746 - # 2 Short offline Completed without error 00% 11744 - SMART Selective self-test log data structure revision number 1 SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS 1 0 0 Not_testing 2 0 0 Not_testing 3 0 0 Not_testing 4 0 0 Not_testing 5 0 0 Not_testing Selective self-test flags (0x0): After scanning selected spans, do NOT read-scan remainder of disk. If Selective self-test is pending on power-up, resume after 0 minute delay.And here's a screenshot with the
Error Log: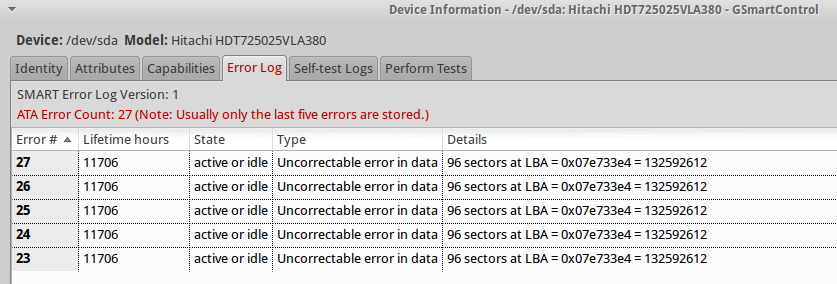
So what is going on? Does the drive have bad sectors or not?
UPDATE1:
Just to be sure I also usedbadblocksas suggested in How do you use badblocks?.First, the non-destructive, 1h-long read-only method:
root@xubuntu:/home/xubuntu# badblocks -sv /dev/sda Checking blocks 0 to 244198583 Checking for bad blocks (read-only test): done Pass completed, 0 bad blocks found. (0/0/0 errors)And then the destructive, 10h-long write method (use with care!):
root@xubuntu:/home/xubuntu# badblocks -wsv /dev/sda Checking for bad blocks in read-write mode From block 0 to 244198583 Testing with pattern 0xaa: done Reading and comparing: done Testing with pattern 0x55: done Reading and comparing: done Testing with pattern 0xff: done Reading and comparing: done Testing with pattern 0x00: done Reading and comparing: done Pass completed, 0 bad blocks found. (0/0/0 errors)As suggested in the answers, it really doesn't look like there are bad sectors on this hard-drive. (Yay!)
-
 bsd over 9 yearsAll platter based drives have bad sectors, and they get marked as bad. Usually the drive knows about the sectors and doesn't report much. I suggest you download the Hitachi specific drive diagnostic utility and let that decide if you have a problem.
bsd over 9 yearsAll platter based drives have bad sectors, and they get marked as bad. Usually the drive knows about the sectors and doesn't report much. I suggest you download the Hitachi specific drive diagnostic utility and let that decide if you have a problem. -
 Michael - sqlbot over 6 years@psusi no, all drives have bad physical sectors from the factory, but they are mapped away by the drive firmware and hidden from the user until no more hidden space is available for remapping.
Michael - sqlbot over 6 years@psusi no, all drives have bad physical sectors from the factory, but they are mapped away by the drive firmware and hidden from the user until no more hidden space is available for remapping. -
 psusi over 6 years@Michael-sqlbot, no... you can read the bad sector counts ( both pending and already reallocated from the spare pool ) with
psusi over 6 years@Michael-sqlbot, no... you can read the bad sector counts ( both pending and already reallocated from the spare pool ) withsmartctl, and on every disk I've ever had ( or been in a system that I administer or have been asked to help fix ) that didn't have an issue, it has been zero. Sometimes I've had a disk develop a handful of them due to a power outage causing the sector to be corrupt, but not physically bad, in which case, simply overwriting it with good data returned the pending count to zero, and left the already reallocated count remaining at zero. -
Michael - sqlbot over 6 years@psusi you are half correct, and my comment was incomplete. There are two lists of bad sectors. The first one is the permanent list. It is populated at the factory and hidden from SMART. They aren't mapped away, they're skipped over. The list you're talking about is the second list, the growth list. All drives have bad sectors from the factory, but they should not show bad sectors from the factory, because the primary list does not show in or contribute to the counters.
-
psusi over 6 years@Michael-sqlbot, according to the SCSI standards, drives can have a separate factory defect list, but if they were not remapped, that would result in a reduction of usable sectors the drive has, causing it to fail to meet its stated specifications, so if they do have such a thing, they are remapped rather than just skipped. In any case, there is no way of knowing whether the drive actually has such a list, at least with ATA disks ( iirc, there was a SCSI command to read the primary list, but no such thing for ATA ).
-
-
landroni over 9 yearsThanks! Couple of questions. "but it seems that the disk dealt with it" and "Ultimately, I managed to unblock the sectors, and after running the extended test". So do you mean that the drive indeed had bad sectors, but managed to "repair" them?
-
 VinoPravin over 9 yearsThere's two types of bad sectors -- logical and physical. You probably had logical ones. You can read more about the difference between the two here -- howtogeek.com/173463/…
VinoPravin over 9 yearsThere's two types of bad sectors -- logical and physical. You probably had logical ones. You can read more about the difference between the two here -- howtogeek.com/173463/… -
landroni over 9 yearsMakes sense, thanks! By any chance, would you mind checking out this related question on a damaged hard-drive? On that drive I get conflicting readings, and I'm not sure what to make of the logs.
-
landroni over 9 yearsI now read the link on bad sectors, and it is very useful to understand what is happening. It would be nice if you included it in the original answer.