Encoding issues for UTF8 CSV file when opening Excel and TextEdit
Solution 1
As @jlarson updated with information that Mac was the biggest culprit we might get some further. Office for Mac has, at least 2011 and back, rather poor support for reading Unicode formats when importing files.
Support for UTF-8 seems to be close to non-existent, have read a tiny few comments about it working, whilst the majority say it does not. Unfortunately I do not have any Mac to test on. So again: The files themselves should be OK as UTF-8, but the import halts the process.
Wrote up a quick test in Javascript for exporting percent escaped UTF-16 little and big endian, with- / without BOM etc.
Code should probably be refactored but should be OK for testing. It might work better then UTF-8. Of course this also usually means bigger data transfers as any glyph is two or four bytes.
You can find a fiddle here:
Note that it does not handle CSV in any particular way. It is mainly meant for pure conversion to data URL having UTF-8, UTF-16 big/little endian and +/- BOM. There is one option in the fiddle to replace commas with tabs, – but believe that would be rather hackish and fragile solution if it works.
Typically use like:
// Initiate
encoder = new DataEnc({
mime : 'text/csv',
charset: 'UTF-16BE',
bom : true
});
// Convert data to percent escaped text
encoder.enc(data);
// Get result
var result = encoder.pay();
There is two result properties of the object:
1.) encoder.lead
This is the mime-type, charset etc. for data URL. Built from options passed to initializer, or one can also say .config({ ... new conf ...}).intro() to re-build.
data:[<MIME-type>][;charset=<encoding>][;base64]
You can specify base64, but there is no base64 conversion (at least not this far).
2.) encoder.buf
This is a string with the percent escaped data.
The .pay() function simply return 1.) and 2.) as one.
Main code:
function DataEnc(a) {
this.config(a);
this.intro();
}
/*
* http://www.iana.org/assignments/character-sets/character-sets.xhtml
* */
DataEnc._enctype = {
u8 : ['u8', 'utf8'],
// RFC-2781, Big endian should be presumed if none given
u16be : ['u16', 'u16be', 'utf16', 'utf16be', 'ucs2', 'ucs2be'],
u16le : ['u16le', 'utf16le', 'ucs2le']
};
DataEnc._BOM = {
'none' : '',
'UTF-8' : '%ef%bb%bf', // Discouraged
'UTF-16BE' : '%fe%ff',
'UTF-16LE' : '%ff%fe'
};
DataEnc.prototype = {
// Basic setup
config : function(a) {
var opt = {
charset: 'u8',
mime : 'text/csv',
base64 : 0,
bom : 0
};
a = a || {};
this.charset = typeof a.charset !== 'undefined' ?
a.charset : opt.charset;
this.base64 = typeof a.base64 !== 'undefined' ? a.base64 : opt.base64;
this.mime = typeof a.mime !== 'undefined' ? a.mime : opt.mime;
this.bom = typeof a.bom !== 'undefined' ? a.bom : opt.bom;
this.enc = this.utf8;
this.buf = '';
this.lead = '';
return this;
},
// Create lead based on config
// data:[<MIME-type>][;charset=<encoding>][;base64],<data>
intro : function() {
var
g = [],
c = this.charset || '',
b = 'none'
;
if (this.mime && this.mime !== '')
g.push(this.mime);
if (c !== '') {
c = c.replace(/[-\s]/g, '').toLowerCase();
if (DataEnc._enctype.u8.indexOf(c) > -1) {
c = 'UTF-8';
if (this.bom)
b = c;
this.enc = this.utf8;
} else if (DataEnc._enctype.u16be.indexOf(c) > -1) {
c = 'UTF-16BE';
if (this.bom)
b = c;
this.enc = this.utf16be;
} else if (DataEnc._enctype.u16le.indexOf(c) > -1) {
c = 'UTF-16LE';
if (this.bom)
b = c;
this.enc = this.utf16le;
} else {
if (c === 'copy')
c = '';
this.enc = this.copy;
}
}
if (c !== '')
g.push('charset=' + c);
if (this.base64)
g.push('base64');
this.lead = 'data:' + g.join(';') + ',' + DataEnc._BOM[b];
return this;
},
// Deliver
pay : function() {
return this.lead + this.buf;
},
// UTF-16BE
utf16be : function(t) { // U+0500 => %05%00
var i, c, buf = [];
for (i = 0; i < t.length; ++i) {
if ((c = t.charCodeAt(i)) > 0xff) {
buf.push(('00' + (c >> 0x08).toString(16)).substr(-2));
buf.push(('00' + (c & 0xff).toString(16)).substr(-2));
} else {
buf.push('00');
buf.push(('00' + (c & 0xff).toString(16)).substr(-2));
}
}
this.buf += '%' + buf.join('%');
// Note the hex array is returned, not string with '%'
// Might be useful if one want to loop over the data.
return buf;
},
// UTF-16LE
utf16le : function(t) { // U+0500 => %00%05
var i, c, buf = [];
for (i = 0; i < t.length; ++i) {
if ((c = t.charCodeAt(i)) > 0xff) {
buf.push(('00' + (c & 0xff).toString(16)).substr(-2));
buf.push(('00' + (c >> 0x08).toString(16)).substr(-2));
} else {
buf.push(('00' + (c & 0xff).toString(16)).substr(-2));
buf.push('00');
}
}
this.buf += '%' + buf.join('%');
// Note the hex array is returned, not string with '%'
// Might be useful if one want to loop over the data.
return buf;
},
// UTF-8
utf8 : function(t) {
this.buf += encodeURIComponent(t);
return this;
},
// Direct copy
copy : function(t) {
this.buf += t;
return this;
}
};
Previous answer:
I do not have any setup to replicate yours, but if your case is the same as @jlarson then the resulting file should be correct.
This answer became somewhat long, (fun topic you say?), but discuss various aspects around the question, what is (likely) happening, and how to actually check what is going on in various ways.
TL;DR:
The text is likely imported as ISO-8859-1, Windows-1252, or the like, and not as UTF-8. Force application to read file as UTF-8 by using import or other means.
PS: The UniSearcher is a nice tool to have available on this journey.
The long way around
The "easiest" way to be 100% sure what we are looking at is to use a hex-editor on the result. Alternatively use hexdump, xxd or the like from command line to view the file. In this case the byte sequence should be that of UTF-8 as delivered from the script.
As an example if we take the script of jlarson it takes the data Array:
data = ['name', 'city', 'state'],
['\u0500\u05E1\u0E01\u1054', 'seattle', 'washington']
This one is merged into the string:
name,city,state<newline>
\u0500\u05E1\u0E01\u1054,seattle,washington<newline>
which translates by Unicode to:
name,city,state<newline>
Ԁסกၔ,seattle,washington<newline>
As UTF-8 uses ASCII as base (bytes with highest bit not set are the same as in ASCII) the only special sequence in the test data is "Ԁסกၔ" which in turn, is:
Code-point Glyph UTF-8
----------------------------
U+0500 Ԁ d4 80
U+05E1 ס d7 a1
U+0E01 ก e0 b8 81
U+1054 ၔ e1 81 94
Looking at the hex-dump of the downloaded file:
0000000: 6e61 6d65 2c63 6974 792c 7374 6174 650a name,city,state.
0000010: d480 d7a1 e0b8 81e1 8194 2c73 6561 7474 ..........,seatt
0000020: 6c65 2c77 6173 6869 6e67 746f 6e0a le,washington.
On second line we find d480 d7a1 e0b8 81e1 8194 which match up with the above:
0000010: d480 d7a1 e0b8 81 e1 8194 2c73 6561 7474 ..........,seatt
| | | | | | | | | | | | | |
+-+-+ +-+-+ +--+--+ +--+--+ | | | | | |
| | | | | | | | | |
Ԁ ס ก ၔ , s e a t t
None of the other characters is mangled either.
Do similar tests if you want. The result should be the similar.
By sample provided —, â€, “
We can also have a look at the sample provided in the question. It is likely to assume that the text is represented in Excel / TextEdit by code-page 1252.
To quote Wikipedia on Windows-1252:
Windows-1252 or CP-1252 is a character encoding of the Latin alphabet, used by default in the legacy components of Microsoft Windows in English and some other Western languages. It is one version within the group of Windows code pages. In LaTeX packages, it is referred to as "ansinew".
Retrieving the original bytes
To translate it back into it's original form we can look at the code page layout, from which we get:
Character: <â> <€> <”> <,> < > <â> <€> < > <,> < > <â> <€> <œ>
U.Hex : e2 20ac 201d 2c 20 e2 20ac 9d 2c 20 e2 20ac 153
T.Hex : e2 80 94 2c 20 e2 80 9d* 2c 20 e2 80 9c
-
Uis short for Unicode -
Tis short for Translated
For example:
â => Unicode 0xe2 => CP-1252 0xe2
” => Unicode 0x201d => CP-1252 0x94
€ => Unicode 0x20ac => CP-1252 0x80
Special cases like 9d does not have a corresponding code-point in CP-1252, these we simply copy directly.
Note: If one look at mangled string by copying the text to a file and doing a hex-dump, save the file with for example UTF-16 encoding to get the Unicode values as represented in the table. E.g. in Vim:
set fenc=utf-16
# Or
set fenc=ucs-2
Bytes to UTF-8
We then combine the result, the T.Hex line, into UTF-8. In UTF-8 sequences the bytes are represented by a leading byte telling us how many subsequent bytes make the glyph. For example if a byte has the binary value 110x xxxx we know that this byte and the next represent one code-point. A total of two. 1110 xxxx tells us it is three and so on. ASCII values does not have the high bit set, as such any byte matching 0xxx xxxx is a standalone. A total of one byte.
0xe2 = 1110 0010bin => 3 bytes => 0xe28094 (em-dash) — 0x2c = 0010 1100bin => 1 byte => 0x2c (comma) , 0x2c = 0010 0000bin => 1 byte => 0x20 (space) 0xe2 = 1110 0010bin => 3 bytes => 0xe2809d (right-dq) ” 0x2c = 0010 1100bin => 1 byte => 0x2c (comma) , 0x2c = 0010 0000bin => 1 byte => 0x20 (space) 0xe2 = 1110 0010bin => 3 bytes => 0xe2809c (left-dq) “
Conclusion; The original UTF-8 string was:
—, ”, “
Mangling it back
We can also do the reverse. The original string as bytes:
UTF-8: e2 80 94 2c 20 e2 80 9d 2c 20 e2 80 9c
Corresponding values in cp-1252:
e2 => â
80 => €
94 => ”
2c => ,
20 => <space>
...
and so on, result:
—, â€, “
Importing to MS Excel
In other words: The issue at hand could be how to import UTF-8 text files into MS Excel, and some other applications. In Excel this can be done in various ways.
- Method one:
Do not save the file with an extension recognized by the application, like .csv, or .txt, but omit it completely or make something up.
As an example save the file as "testfile", with no extension. Then in Excel open the file, confirm that we actually want to open this file, and voilà we get served with the encoding option. Select UTF-8, and file should be correctly read.
- Method two:
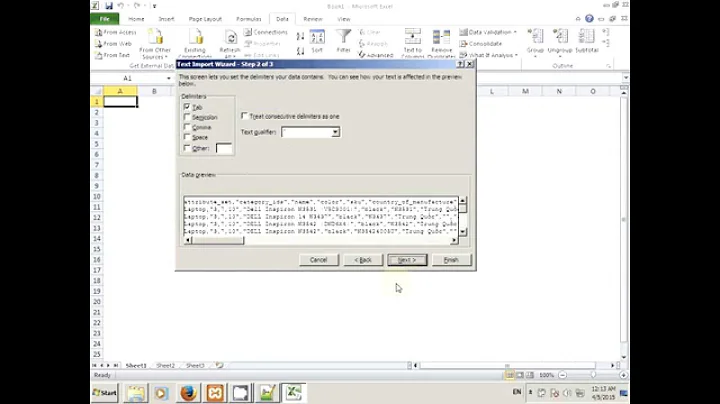
Use import data instead of open file. Something like:
Data -> Import External Data -> Import Data
Select encoding and proceed.
Check that Excel and selected font actually supports the glyph
We can also test the font support for the Unicode characters by using the, sometimes, friendlier clipboard. For example, copy text from this page into Excel:
If support for the code points exist, the text should render fine.
Linux
On Linux, which is primarily UTF-8 in userland this should not be an issue. Using Libre Office Calc, Vim, etc. show the files correctly rendered.
Why it works (or should)
encodeURI from the spec states, (also read sec-15.1.3):
The encodeURI function computes a new version of a URI in which each instance of certain characters is replaced by one, two, three, or four escape sequences representing the UTF-8 encoding of the character.
We can simply test this in our console by, for example saying:
>> encodeURI('Ԁסกၔ,seattle,washington')
<< "%D4%80%D7%A1%E0%B8%81%E1%81%94,seattle,washington"
As we register the escape sequences are equal to the ones in the hex dump above:
%D4%80%D7%A1%E0%B8%81%E1%81%94 (encodeURI in log)
d4 80 d7 a1 e0 b8 81 e1 81 94 (hex-dump of file)
or, testing a 4-byte code:
>> encodeURI('')
<< "%F3%B1%80%81"
If this is does not comply
If nothing of this apply it could help if you added
- Sample of expected input vs mangled output, (copy paste).
- Sample hex-dump of original data vs result file.
Solution 2
I ran into exactly this yesterday. I was developing a button that exports the contents of an HTML table as a CSV download. The functionality of the button itself is almost identical to yours – on click I read the text from the table and create a data URI with the CSV content.
When I tried to open the resulting file in Excel it was clear that the "£" symbol was getting read incorrectly. The 2 byte UTF-8 representation was being processed as ASCII resulting in an unwanted garbage character. Some Googling indicated this was a known issue with Excel.
I tried adding the byte order mark at the start of the string – Excel just interpreted it as ASCII data. I then tried various things to convert the UTF-8 string to ASCII (such as csvData.replace('\u00a3', '\xa3')) but I found that any time the data is coerced to a JavaScript string it will become UTF-8 again. The trick is to convert it to binary and then Base64 encode it without converting back to a string along the way.
I already had CryptoJS in my app (used for HMAC authentication against a REST API) and I was able to use that to create an ASCII encoded byte sequence from the original string then Base64 encode it and create a data URI. This worked and the resulting file when opened in Excel does not display any unwanted characters.
The essential bit of code that does the conversion is:
var csvHeader = 'data:text/csv;charset=iso-8859-1;base64,'
var encodedCsv = CryptoJS.enc.Latin1.parse(csvData).toString(CryptoJS.enc.Base64)
var dataURI = csvHeader + encodedCsv
Where csvData is your CSV string.
There are probably ways to do the same thing without CryptoJS if you don't want to bring in that library but this at least shows it is possible.
Solution 3
I was having a similar issue with data that was pulled into Javascript from a Sharepoint list. It turned out to be something called a "Zero Width Space" character and it was being displayed as †when it was brought into Excel. Apparently, Sharepoint inserts these sometimes when a user hits 'backspace'.
I replaced them with this quickfix:
var mystring = myString.replace(/\u200B/g,'');
It looks like you may have other hidden characters in there. I found the codepoint for the zero-width character in mine by looking at the output string in the Chrome inspector. The inspector couldn't render the character so it replaced it with a red dot. When you hover your mouse over that red dot, it gives you the codepoint (eg. \u200B) and you can just sub in the various codepoints to the invisible characters and remove them that way.
Solution 4
Excel likes Unicode in UTF-16 LE with BOM encoding. Output the correct BOM (FF FE), then convert all your data from UTF-8 to UTF-16 LE.
Windows uses UTF-16 LE internally, so some applications work better with UTF-16 than with UTF-8.
I haven't tried to do that in JS, but there're various scripts on the web to convert UTF-8 to UTF-16. Conversion between UTF variations is pretty easy and takes just a dozen of lines.
Solution 5
button.href = 'data:' + mimeType + ';charset=UTF-8,%ef%bb%bf' + encodedUri;
this should do the trick
Related videos on Youtube
 01 : 02
01 : 02
 02 : 21
02 : 21
 06 : 09
06 : 09
 01 : 16
01 : 16
 01 : 47
01 : 47
 03 : 34
03 : 34
 02 : 02
02 : 02
 01 : 10
01 : 10
Ji Mun
Updated on March 31, 2020Comments
-
Ji Mun about 4 years
I recently added a CSV-download button that takes data from database (Postgres) an array from server (Ruby on Rails), and turns it into a CSV file on the client side (Javascript, HTML5). I'm currently testing the CSV file and I am coming across some encoding issues.
When I view the CSV file via 'less', the file appears fine. But when I open the file in Excel OR TextEdit, I start seeing weird characters like
—, â€, “
appear in the text. Basically, I see the characters that are described here: http://digwp.com/2011/07/clean-up-weird-characters-in-database/
I read that this sort of issue can arise when the Database encoding setting is set to the wrong one. BUT, the database that I am using is set to use UTF8 encoding. And when I debug through the JS codes that create the CSV file, the text appear normal. (This could be a Chrome ability, and less capability)
I'm feeling frustrated because the only thing I am learning from my online search is that there could be many reasons why encoding is not working, I'm not sure which part is at fault (so excuse me as I initially tag numerous things), and nothing I tried has shed new light on my problem.
For reference, here's the JavaScript snippet that creates the CSV file!
$(document).ready(function() { var csvData = <%= raw to_csv(@view_scope, clicks_post).as_json %>; var csvContent = "data:text/csv;charset=utf-8,"; csvData.forEach(function(infoArray, index){ var dataString = infoArray.join(","); csvContent += dataString+ "\n"; }); var encodedUri = encodeURI(csvContent); var button = $('<a>'); button.text('Download CSV'); button.addClass("button right"); button.attr('href', encodedUri); button.attr('target','_blank'); button.attr('download','<%=title%>_25_posts.csv'); $("#<%=title%>_download_action").append(button); });-
jwl about 10 yearsHere is a JSBin that replicates some variations: jsbin.com/wuxeceza/4
-
jwl about 10 yearsPlease note that behavior may vary between OS, Browser, and Excel version so please account for these in your answer if you want the bounty!
-
 user13500 about 10 years@jlarson: Have you changed it? First files had UTF-8 BOM mark ...
user13500 about 10 years@jlarson: Have you changed it? First files had UTF-8 BOM mark ... -
jwl about 10 years@user13500 the UTF-8 BOM marker doesn't seem to help anywhere so it was removed.
-
user13500 about 10 years@jlarson: Well, no, but it is a bit hard to check on if the code base changes while one do tests ... :)
-
user13500 about 10 years@jlarson: What if you copy this text: "U+050x ԀԁԂԃԄԅԆԇԈԉԊԋԌԍԎԏ" and paste it in to the affected application? Do they show correctly?
-
 Marcelo Lujan almost 8 yearsTry adding the BOM first, like var BOM = "\uFEFF"; var csvContent = BOM + csvContent; Before send it to the CSV
Marcelo Lujan almost 8 yearsTry adding the BOM first, like var BOM = "\uFEFF"; var csvContent = BOM + csvContent; Before send it to the CSV
-
-
jwl about 10 yearsWe are trying to do this from the client side. "turns it into a CSV file on the client side (Javascript, HTML5)"
-
goten about 10 yearsI understand that, yet it doesn't necessarily mean that what the server sends to the client is correctly encoded (even if it is utf-8 in database it passes through server)
-
 Patrick Hofman about 10 years+1: Thorough explanation and even if it doesn't help OP, it is very helpful for future reference.
Patrick Hofman about 10 years+1: Thorough explanation and even if it doesn't help OP, it is very helpful for future reference. -
SheetJS about 10 years@jlarson you can use something like github.com/SheetJS/js-codepage to convert between UTF8 and codepage 1252
-
Ji Mun about 10 yearsI feel like I should be able to tackle all sorts of encoding bugs now! Thank you for the detailed explanation and suggestions.
-
user13500 about 10 years@JiMun: Hope at least it can shed some light on the task. It became somewhat long and could be structured better (and there is of course also tons of topics one could include). Also note, if you are not fully aware, that JS uses 16-bit codes with surrogate pairs for values above 16-bit. (If you decide to play with the bytes in JS.)
-
jwl about 10 yearsOK, this doesn't solve the problem but has some very good research so thank you -- bounty is yours @user13500
-
user13500 about 10 years@jlarson: Thanks. But, it's too bad it does not help solving it. Are the files mangled on disk, or is the issue primarily import to Excel?
-
jwl about 10 yearsimport to Excel (especially on Mac) seems to be the issue
-
user13500 about 10 years@jlarson: Somehow missed that comment. Updated with some sample code for UTF-16.
-
 Kim Honoridez over 9 yearshow about when the output should be a csv file in Shift_JIS encoding?
Kim Honoridez over 9 yearshow about when the output should be a csv file in Shift_JIS encoding? -
Francisc over 9 yearsThis is a brilliant answer.
-
Vanco over 8 yearsThanks! You are a rock star. Just saved my behind with this!
-
moonpatrol almost 8 yearsThis may not be the ideal solution to the problem, but it is great for fixing the SharePoint Zero Width space issue