How can I debug "ImagePullBackOff"?
Solution 1
You can use the 'describe pod' syntax
For OpenShift use:
oc describe pod <pod-id>
For vanilla Kubernetes:
kubectl describe pod <pod-id>
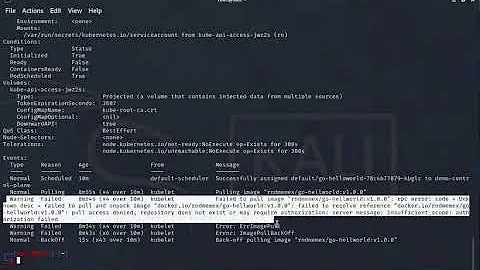
Examine the events of the output.
In my case it shows Back-off pulling image unreachableserver/nginx:1.14.22222
In this case the image unreachableserver/nginx:1.14.22222 can not be pulled from the Internet because there is no Docker registry unreachableserver and the image nginx:1.14.22222 does not exist.
NB: If you do not see any events of interest and the pod has been in the 'ImagePullBackOff' status for a while (seems like more than 60 minutes), you need to delete the pod and look at the events from the new pod.
For OpenShift use:
oc delete pod <pod-id>
oc get pods
oc get pod <new-pod-id>
For vanilla Kubernetes:
kubectl delete pod <pod-id>
kubectl get pods
kubectl get pod <new-pod-id>
Sample output:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 32s default-scheduler Successfully assigned rk/nginx-deployment-6c879b5f64-2xrmt to aks-agentpool-x
Normal Pulling 17s (x2 over 30s) kubelet Pulling image "unreachableserver/nginx:1.14.22222"
Warning Failed 16s (x2 over 29s) kubelet Failed to pull image "unreachableserver/nginx:1.14.22222": rpc error: code = Unknown desc = Error response from daemon: pull access denied for unreachableserver/nginx, repository does not exist or may require 'docker login': denied: requested access to the resource is denied
Warning Failed 16s (x2 over 29s) kubelet Error: ErrImagePull
Normal BackOff 5s (x2 over 28s) kubelet Back-off pulling image "unreachableserver/nginx:1.14.22222"
Warning Failed 5s (x2 over 28s) kubelet Error: ImagePullBackOff
Additional debugging steps
- try to pull the docker image and tag manually on your computer
- Identify the node by doing a 'kubectl/oc get pods -o wide'
- ssh into the node (if you can) that can not pull the docker image
- check that the node can resolve the DNS of the docker registry by performing a ping.
- try to pull the docker image manually on the node
- If you are using a private registry, check that your secret exists and the secret is correct. Your secret should also be in the same namespace. Thanks swenzel
- Some registries have firewalls that limit ip address access. The firewall may block the pull
- Some CIs create deployments with temporary docker secrets. So the secret expires after a few days (You are asking for production failures...)
Solution 2
I faced a similar situation and it turned out that with the actualisation of Docker Desktop I was signed out. After I signed back in, all worked fine again.
Solution 3
Try to edit to see what's wrong (I had the wrong image location):
kubectl edit pods arix-3-yjq9w
Or even delete your pod:
kubectl delete arix-3-yjq9w
Solution 4
I ran into this issue on Google Kubernetes Engine (GKE), and the reason was no credentials for Docker.
Running this resolved it:
gcloud auth configure-docker
Solution 5
On GKE, if the pod is dead, it's best to check for the events. It will show in more detail what the error is about.
In my case, I had:
Failed to pull image "gcr.io/project/imagename@sha256:c8e91af54fc17faa1c49e2a05def5cbabf8f0a67fc558eb6cbca138061a8400a":
rpc error: code = Unknown desc = error pulling image configuration: unknown blob
It turned out the image was damaged somehow. After repushing it and deploying with the new hash, it worked again.
In retrospective, I think the images got damaged, because the bucket in GCP that hosts the images had a clean up policy set on it, and that basically removed the images. As a result the message as above can be seen in events.
Other common issues are a wrong name (gcr.io vs eu.gcr.io) and it can also be that the registry cannot be reached somehow. Again, hints are in the events, the message there should tell you enough.
More general information can be found here (like for authentication):
Related videos on Youtube
 01 : 03
01 : 03
 07 : 28
07 : 28
 09 : 07
09 : 07
 12 : 48
12 : 48
 05 : 08
05 : 08
 10 : 00
10 : 00
 10 : 51
10 : 51
 11 : 40
11 : 40
 04 : 24
04 : 24
 12 : 25
12 : 25
 03 : 38
03 : 38
 07 : 33
07 : 33
 11 : 41
11 : 41
 19 : 46
19 : 46
 12 : 12
12 : 12
Devs love ZenUML
Solution designer at NAB. Founder of ZenUML.com.
Updated on March 31, 2022Comments
-
 Devs love ZenUML about 2 years
Devs love ZenUML about 2 yearsAll of a sudden, I cannot deploy some images which could be deployed before. I got the following pod status:
[root@webdev2 origin]# oc get pods NAME READY STATUS RESTARTS AGE arix-3-yjq9w 0/1 ImagePullBackOff 0 10m docker-registry-2-vqstm 1/1 Running 0 2d router-1-kvjxq 1/1 Running 0 2dThe application just won't start. The pod is not trying to run the container. From the Event page, I have got
Back-off pulling image "172.30.84.25:5000/default/arix@sha256:d326. I have verified that I can pull the image with the tag withdocker pull.I have also checked the log of the last container. It was closed for some reason. I think the pod should at least try to restart it.
I have run out of ideas to debug the issues. What can I check more?
-
Clayton over 8 yearsIs this a multi machine setup? If so verify you can pull from all nodes. If not, turn up logging to --loglevel=5 on the node and restart - you should see information printed describing the attempt to pull the image and any errors included.
-
 lvthillo about 8 yearsWhat came out after restarting with loglevel=5?
lvthillo about 8 yearsWhat came out after restarting with loglevel=5? -
 ItayB almost 8 yearsDid you solve the problem? can someone explain this issue of 'ImagePullBackOff'? (images are existing in my 'docker images')
ItayB almost 8 yearsDid you solve the problem? can someone explain this issue of 'ImagePullBackOff'? (images are existing in my 'docker images') -
Clemens Tolboom over 7 yearsI got this by using the wrong region for my repo. I forgot to add eu. to --image=eu.gcr.io/$PROJECT_ID/...
-
Tara Prasad Gurung over 4 yearsIn my case it was the wrong tag name for the image being passed. I changed the TAG name which solved the issue.
-
Meiki Neumann over 2 yearsIt's a good read solved my problem totally tutorialworks.com/kubernetes-imagepullbackoff
-
-
 swenzel over 5 yearsAlso, in case you use a private image repository, make sure your image pull secrets exist, have no typo and they are in the right namespace.
swenzel over 5 yearsAlso, in case you use a private image repository, make sure your image pull secrets exist, have no typo and they are in the right namespace. -
Donato Szilagyi over 4 yearsIn case of private image repository also make sure that you reference the image pull secrets in your pod using the "imagePullSecrets" entry.
-
gar over 4 yearsThere is also a lengthy blog post describing how to debug this in depth here: managedkube.com/kubernetes/k8sbot/troubleshooting/…
-
Kirk Sefchik about 3 yearsThese instructions are out of date -- kubernetes no longer provides detailed information on imagepullbackoff
-
Kirk Sefchik about 3 yearsYour context only governs which cluster you're connected to. This answer is incorrect.
-
 rjdkolb almost 3 years@KirkSefchik, I think I figured out why you do not see the detailed information. I have updated my answer, thanks.
rjdkolb almost 3 years@KirkSefchik, I think I figured out why you do not see the detailed information. I have updated my answer, thanks. -
 Peter Mortensen over 2 yearsWhat is "actualisation" (in this context)? Can you elaborate?
Peter Mortensen over 2 yearsWhat is "actualisation" (in this context)? Can you elaborate? -
David Louda over 2 yearsan update to a newer version
-
Peter Mortensen over 2 yearsIn what context? Linux? Inside the Docker container? Somewhere else?