How does Dijkstra's Algorithm and A-Star compare?
Solution 1
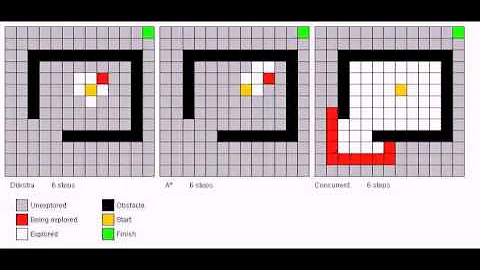
Dijkstra is a special case for A* (when the heuristics is zero).
Solution 2
Dijkstra:
It has one cost function, which is real cost value from source to each node: f(x)=g(x).
It finds the shortest path from source to every other node by considering only real cost.
A* search:
It has two cost function.
g(x): same as Dijkstra. The real cost to reach a nodex.h(x): approximate cost from nodexto goal node. It is a heuristic function. This heuristic function should never overestimate the cost. That means, the real cost to reach goal node from nodexshould be greater than or equalh(x). It is called admissible heuristic.
The total cost of each node is calculated by f(x)=g(x)+h(x)
A* search only expands a node if it seems promising. It only focuses to reach the goal node from the current node, not to reach every other nodes. It is optimal, if the heuristic function is admissible.
So if your heuristic function is good to approximate the future cost, than you will need to explore a lot less nodes than Dijkstra.
Solution 3
What previous poster said, plus because Dijkstra has no heuristic and at each step picks edges with smallest cost it tends to "cover" more of your graph. Because of that Dijkstra could be more useful than A*. Good example is when you have several candidate target nodes, but you don't know, which one is closest (in A* case you would have to run it multiple times: once for each candidate node).
Solution 4
Dijkstra's algorithm would never be used for pathfinding. Using A* is a no-brainer if you can come up with a decent heuristic (usually easy for games, especially in 2D worlds). Depending on the search space, Iterative Deepening A* is sometimes preferable because it uses less memory.
Solution 5
Dijkstra is a special case for A*.
Dijkstra finds the minimum costs from the starting node to all others. A* finds the minimum cost from the start node to the goal node.
Dijkstra's algorithm would never be used for path finding. Using A* one can come up with a decent heuristic. Depending on the search space, iterative A* is is preferable because it uses less memory.
The code for Dijkstra's algorithm is:
// A C / C++ program for Dijkstra's single source shortest path algorithm.
// The program is for adjacency matrix representation of the graph
#include <stdio.h>
#include <limits.h>
// Number of vertices in the graph
#define V 9
// A utility function to find the vertex with minimum distance value, from
// the set of vertices not yet included in shortest path tree
int minDistance(int dist[], bool sptSet[])
{
// Initialize min value
int min = INT_MAX, min_index;
for (int v = 0; v < V; v++)
if (sptSet[v] == false && dist[v] <= min)
min = dist[v], min_index = v;
return min_index;
}
int printSolution(int dist[], int n)
{
printf("Vertex Distance from Source\n");
for (int i = 0; i < V; i++)
printf("%d \t\t %d\n", i, dist[i]);
}
void dijkstra(int graph[V][V], int src)
{
int dist[V]; // The output array. dist[i] will hold the shortest
// distance from src to i
bool sptSet[V]; // sptSet[i] will true if vertex i is included in shortest
// path tree or shortest distance from src to i is finalized
// Initialize all distances as INFINITE and stpSet[] as false
for (int i = 0; i < V; i++)
dist[i] = INT_MAX, sptSet[i] = false;
// Distance of source vertex from itself is always 0
dist[src] = 0;
// Find shortest path for all vertices
for (int count = 0; count < V-1; count++)
{
// Pick the minimum distance vertex from the set of vertices not
// yet processed. u is always equal to src in first iteration.
int u = minDistance(dist, sptSet);
// Mark the picked vertex as processed
sptSet[u] = true;
// Update dist value of the adjacent vertices of the picked vertex.
for (int v = 0; v < V; v++)
// Update dist[v] only if is not in sptSet, there is an edge from
// u to v, and total weight of path from src to v through u is
// smaller than current value of dist[v]
if (!sptSet[v] && graph[u][v] && dist[u] != INT_MAX
&& dist[u]+graph[u][v] < dist[v])
dist[v] = dist[u] + graph[u][v];
}
// print the constructed distance array
printSolution(dist, V);
}
// driver program to test above function
int main()
{
/* Let us create the example graph discussed above */
int graph[V][V] = {{0, 4, 0, 0, 0, 0, 0, 8, 0},
{4, 0, 8, 0, 0, 0, 0, 11, 0},
{0, 8, 0, 7, 0, 4, 0, 0, 2},
{0, 0, 7, 0, 9, 14, 0, 0, 0},
{0, 0, 0, 9, 0, 10, 0, 0, 0},
{0, 0, 4, 14, 10, 0, 2, 0, 0},
{0, 0, 0, 0, 0, 2, 0, 1, 6},
{8, 11, 0, 0, 0, 0, 1, 0, 7},
{0, 0, 2, 0, 0, 0, 6, 7, 0}
};
dijkstra(graph, 0);
return 0;
}
The code for A* algorithm is:
class Node:
def __init__(self,value,point):
self.value = value
self.point = point
self.parent = None
self.H = 0
self.G = 0
def move_cost(self,other):
return 0 if self.value == '.' else 1
def children(point,grid):
x,y = point.point
links = [grid[d[0]][d[1]] for d in [(x-1, y),(x,y - 1),(x,y + 1),(x+1,y)]]
return [link for link in links if link.value != '%']
def manhattan(point,point2):
return abs(point.point[0] - point2.point[0]) + abs(point.point[1]-point2.point[0])
def aStar(start, goal, grid):
#The open and closed sets
openset = set()
closedset = set()
#Current point is the starting point
current = start
#Add the starting point to the open set
openset.add(current)
#While the open set is not empty
while openset:
#Find the item in the open set with the lowest G + H score
current = min(openset, key=lambda o:o.G + o.H)
#If it is the item we want, retrace the path and return it
if current == goal:
path = []
while current.parent:
path.append(current)
current = current.parent
path.append(current)
return path[::-1]
#Remove the item from the open set
openset.remove(current)
#Add it to the closed set
closedset.add(current)
#Loop through the node's children/siblings
for node in children(current,grid):
#If it is already in the closed set, skip it
if node in closedset:
continue
#Otherwise if it is already in the open set
if node in openset:
#Check if we beat the G score
new_g = current.G + current.move_cost(node)
if node.G > new_g:
#If so, update the node to have a new parent
node.G = new_g
node.parent = current
else:
#If it isn't in the open set, calculate the G and H score for the node
node.G = current.G + current.move_cost(node)
node.H = manhattan(node, goal)
#Set the parent to our current item
node.parent = current
#Add it to the set
openset.add(node)
#Throw an exception if there is no path
raise ValueError('No Path Found')
def next_move(pacman,food,grid):
#Convert all the points to instances of Node
for x in xrange(len(grid)):
for y in xrange(len(grid[x])):
grid[x][y] = Node(grid[x][y],(x,y))
#Get the path
path = aStar(grid[pacman[0]][pacman[1]],grid[food[0]][food[1]],grid)
#Output the path
print len(path) - 1
for node in path:
x, y = node.point
print x, y
pacman_x, pacman_y = [ int(i) for i in raw_input().strip().split() ]
food_x, food_y = [ int(i) for i in raw_input().strip().split() ]
x,y = [ int(i) for i in raw_input().strip().split() ]
grid = []
for i in xrange(0, x):
grid.append(list(raw_input().strip()))
next_move((pacman_x, pacman_y),(food_x, food_y), grid)
Related videos on Youtube
 10 : 52
10 : 52
 02 : 46
02 : 46
 04 : 46
04 : 46
 01 : 56
01 : 56
 08 : 31
08 : 31
 20 : 36
20 : 36
 31 : 59
31 : 59
 04 : 14
04 : 14
Comments
-
KingNestor over 2 years
I was looking at what the guys in the Mario AI Competition have been doing and some of them have built some pretty neat Mario bots utilizing the A* (A-Star) Pathing Algorithm.
(Video of Mario A* Bot In Action)My question is, how does A-Star compare with Dijkstra? Looking over them, they seem similar.
Why would someone use one over the other? Especially in the context of pathing in games?
-
SLaks over 14 years
-
Poutrathor over 5 years@SLaks A* uses more memory than dijkstra ? How come if a* only path promising nodes while dijkstra tries them all ?
-
-
KingNestor over 14 yearsWhy would Dijkstra's never be used for pathfinding? Can you elaborate?
-
Shaggy Frog over 14 yearsBecause even if you can come up with a lousy heuristic, you'll do better than Dijkstra. Sometimes even if it's inadmissible. It depends on the domain. Dijkstra also won't work in low-memory situations, whereas IDA* will.
-
Alexandru over 14 yearsA* gives the same results as Dijkstra, but faster when you use a good heuristic. A* algorithm imposes some conditions for to work correctly such as the estimated distance between current node and the final node should be lower than the real distance.
-
Brad Larsen about 14 yearsIf there are several potential goal nodes, one could simply change the goal testing function to include them all. This way, A* would only need to be run once.
-
Robert almost 14 yearsA* is guaranteed to give the shortest path when the heuristic is admissible (always underestimates)
-
Emil over 11 yearsThis is not true. Standard Dijkstra is used to give the shortest path between two points.
-
Emil over 11 yearsThis is not true: A* can look at nodes more than once. In fact, Dijkstra is a special-case of A*...
-
davidtbernal over 11 yearsI found the slides here: webdocs.cs.ualberta.ca/~jonathan/PREVIOUS/Courses/657/Notes/…
-
Kraken about 11 yearsIn dijkstra, we only consider the distance from the source right? And the minimum vertex is taken into consideration?
-
Shahbaz almost 11 years@kraken, yes, that is true.
-
Madmenyo over 10 yearsI thought A* is a special case for Dijkstra where they use a heuristic. Since Dijkstra was there first afaik.
-
 Pieter Geerkens over 10 years@MennoGouw: Yes Dijkstra's algorithm was developed first; but it is a special case of the more general algorithm A*. It is not at all unusual (in fact, probably the norm) for special cases to be discovered first, and then subsequently be generalized .
Pieter Geerkens over 10 years@MennoGouw: Yes Dijkstra's algorithm was developed first; but it is a special case of the more general algorithm A*. It is not at all unusual (in fact, probably the norm) for special cases to be discovered first, and then subsequently be generalized . -
 Ivan Voroshilin over 10 yearsPlease don't mislead, Dijkstra's gives result from s to all other vertices. Thus it works slower.
Ivan Voroshilin over 10 yearsPlease don't mislead, Dijkstra's gives result from s to all other vertices. Thus it works slower. -
 spiralmoon about 10 yearsCheck this one for clarification: stackoverflow.com/questions/21441662/…
spiralmoon about 10 yearsCheck this one for clarification: stackoverflow.com/questions/21441662/… -
seteropere over 7 yearsI second @Emil comment. All you need to do is to stop when removing the destination node from the priority queue and you have the shortest path from the source to destination. This was the original algorithm actually.
-
 BoltzmannBrain over 7 years@JamesMcDowell not necessarily true, not to mention the typical implementations are very different -- BFS using a FIFO stack, dijkstra and A* using a priority queue.
BoltzmannBrain over 7 years@JamesMcDowell not necessarily true, not to mention the typical implementations are very different -- BFS using a FIFO stack, dijkstra and A* using a priority queue. -
BoltzmannBrain over 7 yearsA* and the use of heuristics are discussed well in Norvig and Russel's AI book
-
Erro over 7 yearsDoes this mean that Djikstra and Uniform Cost Search is the same thing?
-
Waylon Flinn about 7 yearsMore precisely: if a target is specified, Dijkstra's finds the shortest path to all nodes that lie on paths shorter than the path to the specified target. The purpose of the heuristic in A* is to prune some of these paths. The effectiveness of the heuristic determines how many are pruned.
-
 Knight0fDragon almost 7 years@seteropere, but what if your destination node is the last node that is searched? It is definitely less efficient, since A*'s heuristics and choosing a priority nodes are what helps make sure that the destination node searched is not the last node on the list
Knight0fDragon almost 7 years@seteropere, but what if your destination node is the last node that is searched? It is definitely less efficient, since A*'s heuristics and choosing a priority nodes are what helps make sure that the destination node searched is not the last node on the list -
 itsjwala over 5 yearsskipping neighbour which are already in closed set will give suboptimal. Trying it on this graph (Its a youtube video example, ignore the language) will give wrong answer.
itsjwala over 5 yearsskipping neighbour which are already in closed set will give suboptimal. Trying it on this graph (Its a youtube video example, ignore the language) will give wrong answer. -
pygosceles about 5 yearsAll search algorithms have a "frontier" and a "visited set". Neither algorithm corrects the path to a node once it is in the visited set: by design, they move nodes from the frontier to the visited set in priority order. Minimal known distances to nodes can be updated only while they are on the frontier. Dijkstra's is a form of best-first search, and a node will never be revisited once it is placed in the "visited" set. A* shares this property, and it uses an auxiliary estimator to choose which nodes on the frontier to prioritize. en.wikipedia.org/wiki/Dijkstra%27s_algorithm