How to plot two histograms together in R?
Solution 1
That image you linked to was for density curves, not histograms.
If you've been reading on ggplot then maybe the only thing you're missing is combining your two data frames into one long one.
So, let's start with something like what you have, two separate sets of data and combine them.
carrots <- data.frame(length = rnorm(100000, 6, 2))
cukes <- data.frame(length = rnorm(50000, 7, 2.5))
# Now, combine your two dataframes into one.
# First make a new column in each that will be
# a variable to identify where they came from later.
carrots$veg <- 'carrot'
cukes$veg <- 'cuke'
# and combine into your new data frame vegLengths
vegLengths <- rbind(carrots, cukes)
After that, which is unnecessary if your data is in long format already, you only need one line to make your plot.
ggplot(vegLengths, aes(length, fill = veg)) + geom_density(alpha = 0.2)

Now, if you really did want histograms the following will work. Note that you must change position from the default "stack" argument. You might miss that if you don't really have an idea of what your data should look like. A higher alpha looks better there. Also note that I made it density histograms. It's easy to remove the y = ..density.. to get it back to counts.
ggplot(vegLengths, aes(length, fill = veg)) +
geom_histogram(alpha = 0.5, aes(y = ..density..), position = 'identity')

Solution 2
Here is an even simpler solution using base graphics and alpha-blending (which does not work on all graphics devices):
set.seed(42)
p1 <- hist(rnorm(500,4)) # centered at 4
p2 <- hist(rnorm(500,6)) # centered at 6
plot( p1, col=rgb(0,0,1,1/4), xlim=c(0,10)) # first histogram
plot( p2, col=rgb(1,0,0,1/4), xlim=c(0,10), add=T) # second
The key is that the colours are semi-transparent.
Edit, more than two years later: As this just got an upvote, I figure I may as well add a visual of what the code produces as alpha-blending is so darn useful:

Solution 3
Here's a function I wrote that uses pseudo-transparency to represent overlapping histograms
plotOverlappingHist <- function(a, b, colors=c("white","gray20","gray50"),
breaks=NULL, xlim=NULL, ylim=NULL){
ahist=NULL
bhist=NULL
if(!(is.null(breaks))){
ahist=hist(a,breaks=breaks,plot=F)
bhist=hist(b,breaks=breaks,plot=F)
} else {
ahist=hist(a,plot=F)
bhist=hist(b,plot=F)
dist = ahist$breaks[2]-ahist$breaks[1]
breaks = seq(min(ahist$breaks,bhist$breaks),max(ahist$breaks,bhist$breaks),dist)
ahist=hist(a,breaks=breaks,plot=F)
bhist=hist(b,breaks=breaks,plot=F)
}
if(is.null(xlim)){
xlim = c(min(ahist$breaks,bhist$breaks),max(ahist$breaks,bhist$breaks))
}
if(is.null(ylim)){
ylim = c(0,max(ahist$counts,bhist$counts))
}
overlap = ahist
for(i in 1:length(overlap$counts)){
if(ahist$counts[i] > 0 & bhist$counts[i] > 0){
overlap$counts[i] = min(ahist$counts[i],bhist$counts[i])
} else {
overlap$counts[i] = 0
}
}
plot(ahist, xlim=xlim, ylim=ylim, col=colors[1])
plot(bhist, xlim=xlim, ylim=ylim, col=colors[2], add=T)
plot(overlap, xlim=xlim, ylim=ylim, col=colors[3], add=T)
}
Here's another way to do it using R's support for transparent colors
a=rnorm(1000, 3, 1)
b=rnorm(1000, 6, 1)
hist(a, xlim=c(0,10), col="red")
hist(b, add=T, col=rgb(0, 1, 0, 0.5) )
The results end up looking something like this:

Solution 4
Already beautiful answers are there, but I thought of adding this. Looks good to me.
(Copied random numbers from @Dirk). library(scales) is needed`
set.seed(42)
hist(rnorm(500,4),xlim=c(0,10),col='skyblue',border=F)
hist(rnorm(500,6),add=T,col=scales::alpha('red',.5),border=F)
The result is...

Update: This overlapping function may also be useful to some.
hist0 <- function(...,col='skyblue',border=T) hist(...,col=col,border=border)
I feel result from hist0 is prettier to look than hist
hist2 <- function(var1, var2,name1='',name2='',
breaks = min(max(length(var1), length(var2)),20),
main0 = "", alpha0 = 0.5,grey=0,border=F,...) {
library(scales)
colh <- c(rgb(0, 1, 0, alpha0), rgb(1, 0, 0, alpha0))
if(grey) colh <- c(alpha(grey(0.1,alpha0)), alpha(grey(0.9,alpha0)))
max0 = max(var1, var2)
min0 = min(var1, var2)
den1_max <- hist(var1, breaks = breaks, plot = F)$density %>% max
den2_max <- hist(var2, breaks = breaks, plot = F)$density %>% max
den_max <- max(den2_max, den1_max)*1.2
var1 %>% hist0(xlim = c(min0 , max0) , breaks = breaks,
freq = F, col = colh[1], ylim = c(0, den_max), main = main0,border=border,...)
var2 %>% hist0(xlim = c(min0 , max0), breaks = breaks,
freq = F, col = colh[2], ylim = c(0, den_max), add = T,border=border,...)
legend(min0,den_max, legend = c(
ifelse(nchar(name1)==0,substitute(var1) %>% deparse,name1),
ifelse(nchar(name2)==0,substitute(var2) %>% deparse,name2),
"Overlap"), fill = c('white','white', colh[1]), bty = "n", cex=1,ncol=3)
legend(min0,den_max, legend = c(
ifelse(nchar(name1)==0,substitute(var1) %>% deparse,name1),
ifelse(nchar(name2)==0,substitute(var2) %>% deparse,name2),
"Overlap"), fill = c(colh, colh[2]), bty = "n", cex=1,ncol=3) }
The result of
par(mar=c(3, 4, 3, 2) + 0.1)
set.seed(100)
hist2(rnorm(10000,2),rnorm(10000,3),breaks = 50)
is

Solution 5
Here is an example of how you can do it in "classic" R graphics:
## generate some random data
carrotLengths <- rnorm(1000,15,5)
cucumberLengths <- rnorm(200,20,7)
## calculate the histograms - don't plot yet
histCarrot <- hist(carrotLengths,plot = FALSE)
histCucumber <- hist(cucumberLengths,plot = FALSE)
## calculate the range of the graph
xlim <- range(histCucumber$breaks,histCarrot$breaks)
ylim <- range(0,histCucumber$density,
histCarrot$density)
## plot the first graph
plot(histCarrot,xlim = xlim, ylim = ylim,
col = rgb(1,0,0,0.4),xlab = 'Lengths',
freq = FALSE, ## relative, not absolute frequency
main = 'Distribution of carrots and cucumbers')
## plot the second graph on top of this
opar <- par(new = FALSE)
plot(histCucumber,xlim = xlim, ylim = ylim,
xaxt = 'n', yaxt = 'n', ## don't add axes
col = rgb(0,0,1,0.4), add = TRUE,
freq = FALSE) ## relative, not absolute frequency
## add a legend in the corner
legend('topleft',c('Carrots','Cucumbers'),
fill = rgb(1:0,0,0:1,0.4), bty = 'n',
border = NA)
par(opar)
The only issue with this is that it looks much better if the histogram breaks are aligned, which may have to be done manually (in the arguments passed to hist).
Related videos on Youtube
 01 : 32
01 : 32
![Histograms in R with ggplot and geom_histogram() [R-Graph Gallery Tutorial]](https://i.ytimg.com/vi/onEumD5xUOE/hq720.jpg?sqp=-oaymwEcCNAFEJQDSFXyq4qpAw4IARUAAIhCGAFwAcABBg==&rs=AOn4CLAukOcV1A97iWPgjt33xkMCLrnMvg) 11 : 34
11 : 34
 04 : 54
04 : 54
 03 : 30
03 : 30
 11 : 39
11 : 39
 03 : 39
03 : 39
 08 : 22
08 : 22
David B
Updated on May 11, 2021Comments
-
David B about 3 years
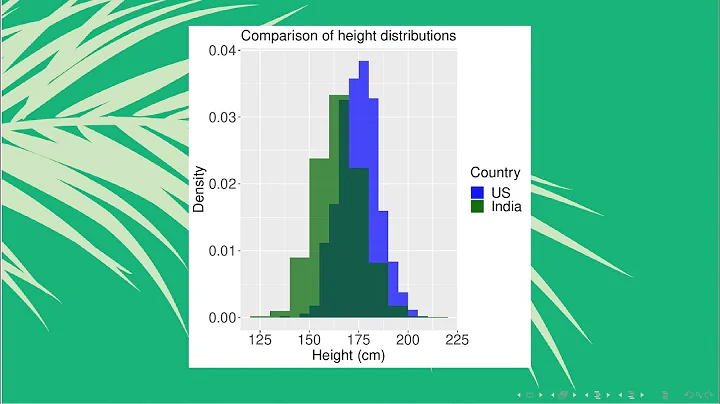
I am using R and I have two data frames: carrots and cucumbers. Each data frame has a single numeric column that lists the length of all measured carrots (total: 100k carrots) and cucumbers (total: 50k cucumbers).
I wish to plot two histograms - carrot length and cucumbers lengths - on the same plot. They overlap, so I guess I also need some transparency. I also need to use relative frequencies not absolute numbers since the number of instances in each group is different.
Something like this would be nice but I don't understand how to create it from my two tables:

-
noel aye almost 14 yearsBtw, which software are you planning to use? For open source, I'd recommend gnuplot.info [gnuplot]. In its documentation, I believe you will find certain technique and sample scripts to do what you want.
-
David B almost 14 yearsI'm using R as the tag suggests (edited post to make this clear)
-
nico almost 14 yearssomeone posted some code snippet to do it in this thread: stackoverflow.com/questions/3485456/…
-
-
 mbq almost 14 yearsIf you'd like to stay with histograms, use
mbq almost 14 yearsIf you'd like to stay with histograms, useggplot(vegLengths, aes(length, fill = veg)) + geom_bar(pos="dodge"). This will make interlaced histograms, like in MATLAB. -
 George Dontas almost 14 yearsVery nice. It also reminded me of that one stackoverflow.com/questions/3485456/…
George Dontas almost 14 yearsVery nice. It also reminded me of that one stackoverflow.com/questions/3485456/… -
David B almost 14 years+1 thank you all, can this be converted to a smoother gistogram (like had.co.nz/ggplot2/graphics/55078149a733dd1a0b42a57faf847036.png)?
-
Lenna over 10 years+1 for an option available on all graphics devices (e.g.
postscript) -
John about 10 yearsWhy did you separate out the
plotcommands? You can put all of those options into thehistcommands and just two it in the two lines. -
 MichaelChirico over 9 yearsupping this because it is a very simple option using base and viable on
MichaelChirico over 9 yearsupping this because it is a very simple option using base and viable onpostscriptdevices. -
MichaelChirico over 9 yearsUpping this because this answer is the only one (besides those in
ggplot) which directly accounts for if your two histograms have substantially different sample sizes. -
Shadow almost 9 yearsThx for the answer! The 'position="identity"' part is actually important as otherwise the bars are stacked which is misleading when combined with a density that by default seems to be "identity", i.e., overlayed as opposed to stacked.
-
 SmallChess over 8 years@John How would you do it?
SmallChess over 8 years@John How would you do it? -
John over 8 yearsPut the options in the
plotcommand directly into the hist command as I said. Posting the code isn't what comments are for. -
Deruijter over 7 yearsI like this method, note that you can synchronize breaks by defining them with seq(). For example:
breaks=seq(min(data$some_property), max(data$some_property), by=(max_prop - min_prop)/20) -
 Admin almost 3 years@John Why separate? I can't read Dirk's mind, but I would write it like that because the code is more clearly readable that way. There is one line for the calculation (hist) and one line for the graphical representation (plot).
Admin almost 3 years@John Why separate? I can't read Dirk's mind, but I would write it like that because the code is more clearly readable that way. There is one line for the calculation (hist) and one line for the graphical representation (plot).
{kind=link}