How to version control a record in a database
Solution 1
Let's say you have a FOO table that admins and users can update. Most of the time you can write queries against the FOO table. Happy days.
Then, I would create a FOO_HISTORY table. This has all the columns of the FOO table. The primary key is the same as FOO plus a RevisionNumber column. There is a foreign key from FOO_HISTORY to FOO. You might also add columns related to the revision such as the UserId and RevisionDate. Populate the RevisionNumbers in an ever-increasing fashion across all the *_HISTORY tables (i.e. from an Oracle sequence or equivalent). Do not rely on there only being one change in a second (i.e. do not put RevisionDate into the primary key).
Now, every time you update FOO, just before you do the update you insert the old values into FOO_HISTORY. You do this at some fundamental level in your design so that programmers can't accidentally miss this step.
If you want to delete a row from FOO you have some choices. Either cascade and delete all the history, or perform a logical delete by flagging FOO as deleted.
This solution is good when you are largely interested in the current values and only occasionally in the history. If you always need the history then you can put effective start and end dates and keep all the records in FOO itself. Every query then needs to check those dates.
Solution 2
I think you are looking for versioning the content of database records (as StackOverflow does when someone edits a question/answer). A good starting point might be looking at some database model that uses revision tracking.
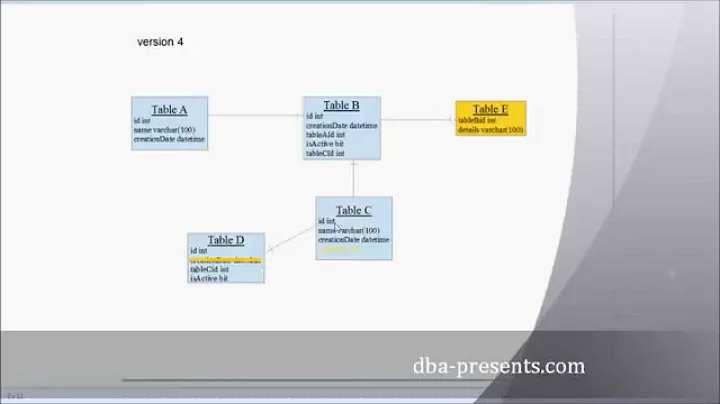
The best example that comes to mind is MediaWiki, the Wikipedia engine. Compare the database diagram here, particularly the revision table.
Depending on what technologies you're using, you'll have to find some good diff/merge algorithms.
Check this question if it's for .NET.
Solution 3
In the BI world, you could accomplish this by adding a startDate and endDate to the table you want to version. When you insert the first record into the table, the startDate is populated, but the endDate is null. When you insert the second record, you also update the endDate of the first record with the startDate of the second record.
When you want to view the current record, you select the one where endDate is null.
This is sometimes called a type 2 Slowly Changing Dimension. See also TupleVersioning
Solution 4
Upgrade to SQL 2008.
Try using SQL Change Tracking, in SQL 2008. Instead of timestamping and tombstone column hacks, you can use this new feature for tracking changes on data in your database.
Solution 5
Just wanted to add that one good solution to this problem is to use a Temporal database. Many database vendors offer this feature either out of the box or via an extension. I've successfully used the temporal table extension with PostgreSQL but others have it too. Whenever you update a record in the database, the database holds on to the previous version of that record too.
Related videos on Youtube
 07 : 16
07 : 16
 13 : 04
13 : 04
 05 : 03
05 : 03
 07 : 11
07 : 11
 06 : 19
06 : 19
 13 : 49
13 : 49
 29 : 52
29 : 52
 04 : 53
04 : 53
Comments
-
Mes almost 3 years
Let's say that I have a record in the database and that both admin and normal users can do updates.
Can anyone suggest a good approach/architecture on how to version control every change in this table so it's possible to roll back a record to a previous revision?
-
Marco Eckstein over 3 years
-
-
Mes over 15 yearsWon't my table grow quite large using this approach?
-
 ConcernedOfTunbridgeWells over 15 yearsYou can do the audit table updating with database triggers if your data access layer doesn't directly support it. Also, it's not hard to build a code generator to make the triggers that uses introspection from the system data dictionary.
ConcernedOfTunbridgeWells over 15 yearsYou can do the audit table updating with database triggers if your data access layer doesn't directly support it. Also, it's not hard to build a code generator to make the triggers that uses introspection from the system data dictionary. -
ConcernedOfTunbridgeWells over 15 yearsYes, but you can deal with that by indexing and/or partitioning the table. Also, there will only be a small handful of large tables. Most will be much smaller.
-
Nerdfest over 15 yearsI woyuld recommend that you actually insert the new data, not the previous, so the history table has all of the data. Although it stores redyundent data, it eliminates the special cases required to deal with searching in both tables when historical data is required.
-
Neil Barnwell over 15 yearsPersonally I'd recommend not deleting anything (defer this to a specific housekeeping activity) and have an "action type" column to specify whether it is insert/update/delete. For a delete you copy the row as normal, but put "delete" in the action type column.
-
Hydrargyrum about 11 yearsIf the HISTORY table includes the current values, why not just define a view which shows only the most-current-version from the HISTORY table? Would that cause performance problems vs. maintaining a separate table?
-
E_the_Shy about 11 years@Hydrargyrum A table holding the current values will perform better than a view of the historic table. You might also want to define foreign keys referencing the current values.
-
 Jasen about 9 years
Jasen about 9 yearsThere is a foreign key from FOO_HISTORY to FOO': bad idea, I would like to delete records from foo without changing history. the history table should be insert-only in normal use. -
 pim over 5 yearsIf I'm not mistaken the only downfall here is that it limits changes to once per second correct?
pim over 5 yearsIf I'm not mistaken the only downfall here is that it limits changes to once per second correct? -
Huntaz556 over 5 years@pimbrouwers yes, it ultimately depends on the precision of the fields and the function that populates them.
-
James over 3 yearsWill this not result in massively ballooning your data size?
-
 lazarus over 2 yearscame up with the same approach, I believe you are not maintaining field here , I mean versioning based on the fields but taking into account a record state change in general
lazarus over 2 yearscame up with the same approach, I believe you are not maintaining field here , I mean versioning based on the fields but taking into account a record state change in general -
 lanartri almost 2 yearsone problem is that architecture defeats base advantages of RDBMS, like referential integrity and duplicates prevention
lanartri almost 2 yearsone problem is that architecture defeats base advantages of RDBMS, like referential integrity and duplicates prevention -
Huntaz556 almost 2 years@iDevlop A generated ID column (that is not part of the data) can be used as the primary key for reference in other tables. UNIQUE and/or CHECK constraints and can preserve the natural integrity of the data while triggers can ensure the changes always move forward in time without gaps.