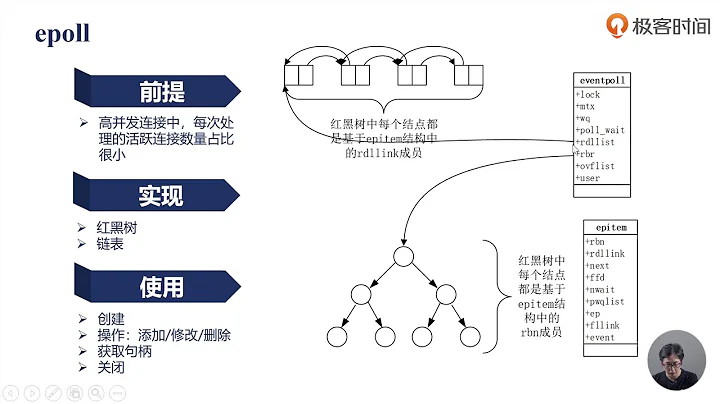
poll vs. epoll insight
Solution 1
Always use poll unless all of the following are satisfied:
- You can ensure you're on a (Linux) system that has
epollor you provide a fallback for systems that don't. - You have a huge number of file descriptors active (at least 1000-10000).
- The set of file descriptors you're working with is stable over a long time period (adding/removing file descriptors from the
epolllist is just as expensive as apolloperation, since it requires entering/leaving kernelspace).
Solution 2
First of all, poll(2) is only level-triggered, but epoll(4) can be used as either edge- or level-triggered interface.
Now complexity: poll complexity regarding number of watched descriptors (fds) is O(n) as it scans all the fds every time when a 'ready' event occurs, epoll is basically O(1) as it doesn't do the linear scan over all the watched descriptors.
In terms of portability - as epoll is Linux-specific I would suggest checking out libev and libevent libraries.
Also, check out Dan Kegel's excellent writeup: "The C10K problem".
Solution 3
epoll(7) summarizes it succinctly: epoll "scales well to large numbers of watched file descriptors." However, poll is a POSIX standard interface, so use that when portability is required.
Related videos on Youtube
 24 : 29
24 : 29
 12 : 01
12 : 01
 20 : 00
20 : 00
 09 : 13
09 : 13
 01 : 01 : 11
01 : 01 : 11
 14 : 35
14 : 35
 16 : 28
16 : 28
 03 : 56
03 : 56
Comments
-
Cartesius00 over 3 years
Are there some simple rules of thumb when to use
pollvs.epollin a low-latency environment?epollshould have higher overhead if only few of file-descriptors is monitored. Please, give some insight, answers "check it yourself" put elsewhere.-
 CodeClown42 over 11 yearsPersonal anecdote: my results testing epoll vs. poll in a single process (no threads, no forks) asynchronous http server (ie, short connection times, <1000 concurrent sockets, giving ~10000 requests/sec) was that the difference between the two is negligible. See my comment to plaes's answer for why.
CodeClown42 over 11 yearsPersonal anecdote: my results testing epoll vs. poll in a single process (no threads, no forks) asynchronous http server (ie, short connection times, <1000 concurrent sockets, giving ~10000 requests/sec) was that the difference between the two is negligible. See my comment to plaes's answer for why.
-
-
Cartesius00 over 12 yearsYes, it scales, but if the number of fds is small,
pollshould be faster. -
PlasmaHH over 12 years@James: I really would like to see some benchmarks about this. From personal experience I would say that given you do something as a reaction on the event, there is no much difference. Given that you have to maintain the poll vector yourself, I would even guess that epoll is faster.The important difference is, as stated in this answer, that poll is POSIX and thus more portable. epoll has also the advantage of offering a few more features.
-
CodeClown42 over 11 yearsI believe the point about epoll and big O notation is not about the internals of either function, so it is incorrect to say that "poll scans all the descriptors whereas epoll does not". Both of them potentially trigger on a single event. However, with poll, the user then has no choice but to iterate thru the entire list submitted to find the events, whereas with epoll you get a list returned containing only the actual events. This means if the server is very busy, there is no advantage to epoll. However, if you are maintaining a very large number of descriptors over a long time...
-
CodeClown42 over 11 years...and most of them are idle most of the time, epoll will have an advantage if you have very rapid events involving only a few connections. Ie, the O(whatever) is about what's possible for the user implementation, not the actual behaviour of poll/epoll.
-
 Nawaz over 3 yearsThe most important point: poll complexity regarding number of watched descriptors (fds) is O(n) as it scans all the fds every time when a 'ready' event occurs, epoll is basically O(1) as it doesn't do the linear scan over all the watched descriptors.. So
Nawaz over 3 yearsThe most important point: poll complexity regarding number of watched descriptors (fds) is O(n) as it scans all the fds every time when a 'ready' event occurs, epoll is basically O(1) as it doesn't do the linear scan over all the watched descriptors.. Soepollscales better thanpoll() -
 xryl669 about 3 yearsFrom my test, poll is not O(N). If any descriptor match the event, it returns immediately. It's a worst case O(N).
xryl669 about 3 yearsFrom my test, poll is not O(N). If any descriptor match the event, it returns immediately. It's a worst case O(N). -
xryl669 about 3 yearsWhile with epoll, you set the maximum number of event you are waiting for so it's O(m) with m < N in the worst case.