Pytorch preferred way to copy a tensor
Solution 1
TL;DR
Use .clone().detach() (or preferrably .detach().clone())
If you first detach the tensor and then clone it, the computation path is not copied, the other way around it is copied and then abandoned. Thus,
.detach().clone()is very slightly more efficient.-- pytorch forums
as it's slightly fast and explicit in what it does.
Using perflot, I plotted the timing of various methods to copy a pytorch tensor.
y = tensor.new_tensor(x) # method a
y = x.clone().detach() # method b
y = torch.empty_like(x).copy_(x) # method c
y = torch.tensor(x) # method d
y = x.detach().clone() # method e
The x-axis is the dimension of tensor created, y-axis shows the time. The graph is in linear scale. As you can clearly see, the tensor() or new_tensor() takes more time compared to other three methods.
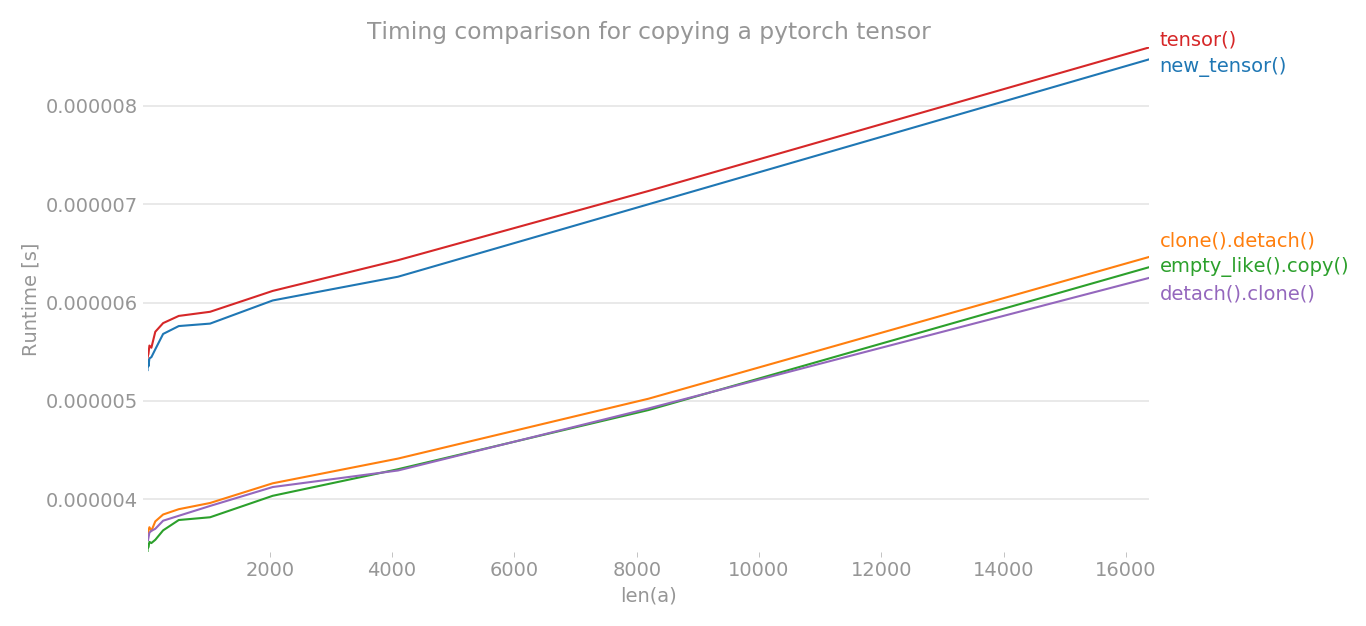
Note: In multiple runs, I noticed that out of b, c, e, any method can have lowest time. The same is true for a and d. But, the methods b, c, e consistently have lower timing than a and d.
import torch
import perfplot
perfplot.show(
setup=lambda n: torch.randn(n),
kernels=[
lambda a: a.new_tensor(a),
lambda a: a.clone().detach(),
lambda a: torch.empty_like(a).copy_(a),
lambda a: torch.tensor(a),
lambda a: a.detach().clone(),
],
labels=["new_tensor()", "clone().detach()", "empty_like().copy()", "tensor()", "detach().clone()"],
n_range=[2 ** k for k in range(15)],
xlabel="len(a)",
logx=False,
logy=False,
title='Timing comparison for copying a pytorch tensor',
)
Solution 2
According to Pytorch documentation #a and #b are equivalent. It also say that
The equivalents using clone() and detach() are recommended.
So if you want to copy a tensor and detach from the computation graph you should be using
y = x.clone().detach()
Since it is the cleanest and most readable way. With all other version there is some hidden logic and it is also not 100% clear what happens to the computation graph and gradient propagation.
Regarding #c: It seems a bit to complicated for what is actually done and could also introduces some overhead but I am not sure about that.
Edit: Since it was asked in the comments why not just use .clone().
From the pytorch docs
Unlike copy_(), this function is recorded in the computation graph. Gradients propagating to the cloned tensor will propagate to the original tensor.
So while .clone() returns a copy of the data it keeps the computation graph and records the clone operation in it. As mentioned this will lead to gradient propagated to the cloned tensor also propagate to the original tensor. This behavior can lead to errors and is not obvious. Because of these possible side effects a tensor should only be cloned via .clone() if this behavior is explicitly wanted. To avoid these side effects the .detach() is added to disconnect the computation graph from the cloned tensor.
Since in general for a copy operation one wants a clean copy which can't lead to unforeseen side effects the preferred way to copy a tensors is .clone().detach().
Solution 3
Pytorch '1.1.0' recommends #b now and shows warning for #d
Solution 4
One example to check if the tensor is copied:
import torch
def samestorage(x,y):
if x.storage().data_ptr()==y.storage().data_ptr():
print("same storage")
else:
print("different storage")
a = torch.ones((1,2), requires_grad=True)
print(a)
b = a
c = a.data
d = a.detach()
e = a.data.clone()
f = a.clone()
g = a.detach().clone()
i = torch.empty_like(a).copy_(a)
j = torch.tensor(a) # UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
print("a:",end='');samestorage(a,a)
print("b:",end='');samestorage(a,b)
print("c:",end='');samestorage(a,c)
print("d:",end='');samestorage(a,d)
print("e:",end='');samestorage(a,e)
print("f:",end='');samestorage(a,f)
print("g:",end='');samestorage(a,g)
print("i:",end='');samestorage(a,i)
Out:
tensor([[1., 1.]], requires_grad=True)
a:same storage
b:same storage
c:same storage
d:same storage
e:different storage
f:different storage
g:different storage
i:different storage
j:different storage
The tensor is copied if the different storage shows up. PyTorch has almost 100 different constructors, so you may add many more ways.
If I would need to copy a tensor I would just use copy(), this copies also the AD related info, so if I would need to remove AD related info I would use:
y = x.clone().detach()
Related videos on Youtube
 17 : 40
17 : 40
 18 : 28
18 : 28
 55 : 33
55 : 33
 10 : 17
10 : 17
 39 : 13
39 : 13
 08 : 26
08 : 26
dkv
Updated on May 09, 2022Comments
-
 dkv about 1 year
dkv about 1 yearThere seems to be several ways to create a copy of a tensor in Pytorch, including
y = tensor.new_tensor(x) #a y = x.clone().detach() #b y = torch.empty_like(x).copy_(x) #c y = torch.tensor(x) #dbis explicitly preferred overaanddaccording to a UserWarning I get if I execute eitheraord. Why is it preferred? Performance? I'd argue it's less readable.Any reasons for/against using
c?-
 Shihab Shahriar Khan over 4 yearsone advantage of
Shihab Shahriar Khan over 4 yearsone advantage ofbis that it makes explicit the fact thatyis no more part of computational graph i.e. doesn't require gradient.cis different from all 3 in thatystill requires grad. -
dkv over 4 yearsHow about
torch.empty_like(x).copy_(x).detach()- is that the same asa/b/d? I recognize this is not a smart way to do it, I'm just trying to understand how the autograd works. I'm confused by the docs forclone()which say "Unlike copy_(), this function is recorded in the computation graph," which made me thinkcopy_()would not require grad. -
 cleros about 4 yearsThere's a pretty explicit note in the docs:
cleros about 4 yearsThere's a pretty explicit note in the docs:When data is a tensor x, new_tensor() reads out ‘the data’ from whatever it is passed, and constructs a leaf variable. Therefore tensor.new_tensor(x) is equivalent to x.clone().detach() and tensor.new_tensor(x, requires_grad=True) is equivalent to x.clone().detach().requires_grad_(True). The equivalents using clone() and detach() are recommended. -
 macharya almost 4 yearsPytorch '1.1.0' recommends #b now and shows warning in #d
macharya almost 4 yearsPytorch '1.1.0' recommends #b now and shows warning in #d -
 Shagun Sodhani over 3 years@ManojAcharya maybe consider adding your comment as an answer here.
Shagun Sodhani over 3 years@ManojAcharya maybe consider adding your comment as an answer here. -
 Charlie Parker about 3 yearswhat about
Charlie Parker about 3 yearswhat about.clone()by itself?
-
-
 becko over 3 yearsWhy is
becko over 3 yearsWhy isdetach()required? -
 Nopileos over 3 yearsFrom the docs "Unlike copy_(), this function is recorded in the computation graph. Gradients propagating to the cloned tensor will propagate to the original tensor.". So to really copy the tensor you want to detach it, or you might get some unwanted gradient updates, you don't know where they coming from.
Nopileos over 3 yearsFrom the docs "Unlike copy_(), this function is recorded in the computation graph. Gradients propagating to the cloned tensor will propagate to the original tensor.". So to really copy the tensor you want to detach it, or you might get some unwanted gradient updates, you don't know where they coming from. -
Charlie Parker about 3 yearswhat about
.clone()by itself? -
Charlie Parker about 3 yearswhat about
.clone()by itself? -
Nopileos about 3 yearsI added some text explaining why not clone by itself. Hope this answers the question.
-
macharya about 3 yearsclone by itself will also keep the variable attached to the original graph
-
 gebbissimo almost 3 yearsStupid question, but why do we need clone()? Do otherwise both tensors point to the same raw data?
gebbissimo almost 3 yearsStupid question, but why do we need clone()? Do otherwise both tensors point to the same raw data? -
gebbissimo almost 3 years