Specify dtype option on import or set low_memory=False
18,934
This solved my problem from here
dashboard_df = pd.read_csv(p_file, sep=',', error_bad_lines=False, index_col=False, dtype='unicode')
Could anyone explain this answer to me tough?
Related videos on Youtube
 18 : 15
18 : 15
How to Process Millions of CSV Rows??? | 3 Easiest Steps...
 06 : 05
06 : 05
PYTHONPATH in Windows: How to import custom python files/modules
 13 : 40
13 : 40
CHANGE COLUMN DTYPE | How to change the datatype of a column in Pandas (2020)
 01 : 37
01 : 37
How to PYTHON : Pandas read_csv low_memory and dtype options
 10 : 16
10 : 16
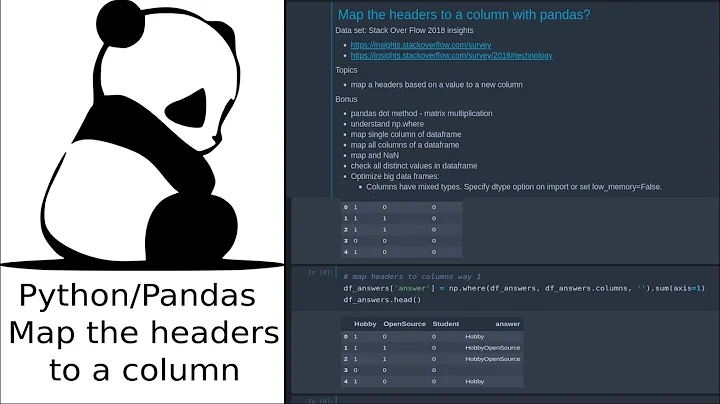
Map the headers to a column with pandas?
Author by
Elias K.
Updated on August 25, 2022Comments
-
Elias K. over 1 year
I am using the following code:
df = pd.read_csv('/Python Test/AcquirerRussell3000.csv')I have the following type of data:
18.07.2000 27.1875 0 08.08.2000 25.3125 0.1 05.09.2000 \ 0 19.07.00 26.6250 -0.020690 09.08.00 25.2344 -0.003085 06.09.00 1 20.07.00 26.6250 0.000000 10.08.00 25.1406 -0.003717 07.09.00 2 21.07.00 25.6875 -0.035211 11.08.00 25.5781 0.017402 08.09.00 3 24.07.00 26.2500 0.021898 14.08.00 25.4375 -0.005497 11.09.00 4 25.07.00 26.6875 0.016667 15.08.00 25.5625 0.004914 12.09.00I am getting the following error:
Pythone Test/untitled0.py:1: DtypeWarning: Columns (long list of numbers) have mixed types. Specify dtype option on import or set low_memory=False.So every 3rd column is a date the rest are numbers. I guess there is no single dtype since dates are strings and the rest is a float or int? I have about 5000 columns or more and around 400 rows.
I have seen similar questions to this but dont quite know how to apply this to my data. Furthermore I want to run the following code after to stack the data frame.
a = np.arange(len(df.columns)) df.columns = [a % 3, a // 3] df = df.stack().reset_index(drop=True) df.to_csv('AcquirerRussell3000stacked.csv', sep=',')What dtype should I use? Or should I just set low_memory to false?
-
 Andrey Kurnikovs over 2 yearsit looks like "dtype='unicode'" does the thing
Andrey Kurnikovs over 2 yearsit looks like "dtype='unicode'" does the thing