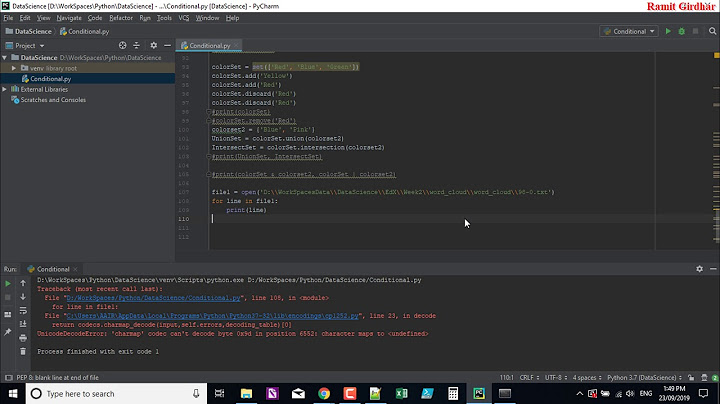
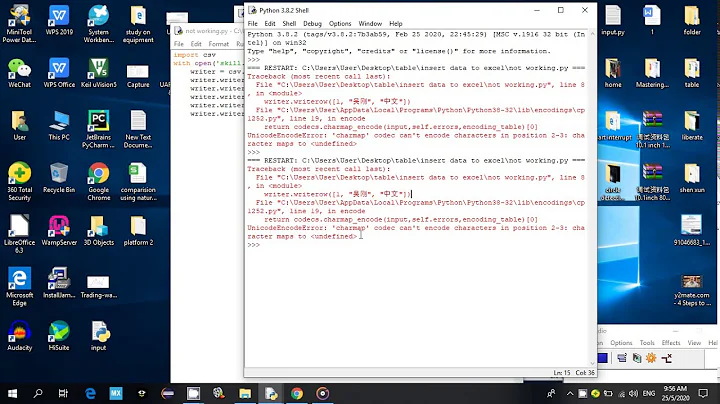
UnicodeEncodeError: 'charmap' codec can't encode - character maps to <undefined>, print function
Solution 1
I see three solutions to this:
Change the output encoding, so it will always output UTF-8. See e.g. Setting the correct encoding when piping stdout in Python, but I could not get these example to work.
-
Following example code makes the output aware of your target charset.
# -*- coding: utf-8 -*- import sys print sys.stdout.encoding print u"Stöcker".encode(sys.stdout.encoding, errors='replace') print u"Стоескер".encode(sys.stdout.encoding, errors='replace')This example properly replaces any non-printable character in my name with a question mark.
If you create a custom print function, e.g. called
myprint, using that mechanisms to encode output properly you can simply replace print withmyprintwhereever necessary without making the whole code look ugly. -
Reset the output encoding globally at the begin of the software:
The page http://www.macfreek.nl/memory/Encoding_of_Python_stdout has a good summary what to do to change output encoding. Especially the section "StreamWriter Wrapper around Stdout" is interesting. Essentially it says to change the I/O encoding function like this:
In Python 2:
if sys.stdout.encoding != 'cp850': sys.stdout = codecs.getwriter('cp850')(sys.stdout, 'strict') if sys.stderr.encoding != 'cp850': sys.stderr = codecs.getwriter('cp850')(sys.stderr, 'strict')In Python 3:
if sys.stdout.encoding != 'cp850': sys.stdout = codecs.getwriter('cp850')(sys.stdout.buffer, 'strict') if sys.stderr.encoding != 'cp850': sys.stderr = codecs.getwriter('cp850')(sys.stderr.buffer, 'strict')If used in CGI outputting HTML you can replace 'strict' by 'xmlcharrefreplace' to get HTML encoded tags for non-printable characters.
Feel free to modify the approaches, setting different encodings, .... Note that it still wont work to output non-specified data. So any data, input, texts must be correctly convertable into unicode:
# -*- coding: utf-8 -*- import sys import codecs sys.stdout = codecs.getwriter("iso-8859-1")(sys.stdout, 'xmlcharrefreplace') print u"Stöcker" # works print "Stöcker".decode("utf-8") # works print "Stöcker" # fails
Solution 2
Based on Dirk Stöcker's answer, here's a neat wrapper function for Python 3's print function. Use it just like you would use print.
As an added bonus, compared to the other answers, this won't print your text as a bytearray ('b"content"'), but as normal strings ('content'), because of the last decode step.
def uprint(*objects, sep=' ', end='\n', file=sys.stdout):
enc = file.encoding
if enc == 'UTF-8':
print(*objects, sep=sep, end=end, file=file)
else:
f = lambda obj: str(obj).encode(enc, errors='backslashreplace').decode(enc)
print(*map(f, objects), sep=sep, end=end, file=file)
uprint('foo')
uprint(u'Antonín Dvořák')
uprint('foo', 'bar', u'Antonín Dvořák')
Solution 3
For debugging purposes, you could use print(repr(data)).
To display text, always print Unicode. Don't hardcode the character encoding of your environment such as Cp850 inside your script. To decode the HTTP response, see A good way to get the charset/encoding of an HTTP response in Python.
To print Unicode to Windows console, you could use win-unicode-console package.
Solution 4
I dug deeper into this and found the best solutions are here.
http://blog.notdot.net/2010/07/Getting-unicode-right-in-Python
In my case I solved "UnicodeEncodeError: 'charmap' codec can't encode character "
original code:
print("Process lines, file_name command_line %s\n"% command_line))
New code:
print("Process lines, file_name command_line %s\n"% command_line.encode('utf-8'))
Solution 5
If you are using Windows command line to print the data, you should use
chcp 65001
This worked for me!
Related videos on Youtube
 01 : 15
01 : 15
 13 : 03
13 : 03
![[SOLVED] UnicodeEncodeError: 'charmap' codec can't encode character...](https://i.ytimg.com/vi/TumTf8-wY1k/hq720.jpg?sqp=-oaymwEcCNAFEJQDSFXyq4qpAw4IARUAAIhCGAFwAcABBg==&rs=AOn4CLDxAJJVfjJXkcss8mnp2RS0kfxoAQ) 01 : 13
01 : 13
 01 : 04
01 : 04
 01 : 39
01 : 39
 01 : 44
01 : 44
Carlos Eugenio Thompson Pinzón
Human being, or so they say. A soul that likes to know about computers and solving problems with them, attempting a living as freelance developer.
Updated on July 18, 2022Comments
-
Carlos Eugenio Thompson Pinzón almost 2 years
I am writing a Python (Python 3.3) program to send some data to a webpage using POST method. Mostly for debugging process I am getting the page result and displaying it on the screen using
print()function.The code is like this:
conn.request("POST", resource, params, headers) response = conn.getresponse() print(response.status, response.reason) data = response.read() print(data.decode('utf-8'));the
HTTPResponse.read()method returns abyteselement encoding the page (which is a well formated UTF-8 document) It seemed okay until I stopped using IDLE GUI for Windows and used the Windows console instead. The returned page has a U+2014 character (em-dash) which the print function translates well in the Windows GUI (I presume Code Page 1252) but does not in the Windows Console (Code Page 850). Given thestrictdefault behavior I get the following error:UnicodeEncodeError: 'charmap' codec can't encode character '\u2014' in position 10248: character maps to <undefined>I could fix it using this quite ugly code:
print(data.decode('utf-8').encode('cp850','replace').decode('cp850'))Now it replace the offending character "—" with a
?. Not the ideal case (a hyphen should be a better replacement) but good enough for my purpose.There are several things I do not like from my solution.
- The code is ugly with all that decoding, encoding, and decoding.
- It solves the problem for just this case. If I port the program for a system using some other encoding (latin-1, cp437, back to cp1252, etc.) it should recognize the target encoding. It does not. (for instance, when using again the IDLE GUI, the emdash is also lost, which didn't happen before)
- It would be nicer if the emdash translated to a hyphen instead of a interrogation bang.
The problem is not the emdash (I can think of several ways to solve that particularly problem) but I need to write robust code. I am feeding the page with data from a database and that data can come back. I can anticipate many other conflicting cases: an 'Á' U+00c1 (which is possible in my database) could translate into CP-850 (DOS/Windows Console encodign for Western European Languages) but not into CP-437 (encoding for US English, which is default in many Windows instalations).
So, the question:
Is there a nicer solution that makes my code agnostic from the output interface encoding?
-
jfs over 7 years
-
 Sreeragh A R about 6 yearsCheck this answer stackoverflow.com/a/49004993/5774004
Sreeragh A R about 6 yearsCheck this answer stackoverflow.com/a/49004993/5774004 -
Yuri about 6 yearsyou are totally right, this is ugly but works like a charm, in my case using latin-1 print(data.decode('cp850').encode('latin-1','replace').decode('latin-1'))
-
Carlos Eugenio Thompson Pinzón about 11 yearsI currently not have my Windows test platform, but I tested in Linux (Ubuntu), with my terminal set to UTF-8 and it worked okay. However I changed my terminal to ISO-8859-15 and it doesn't print right. The output went as: UTF-8 Stöcker СÑПеÑкеÑ
-
Dirk Stöcker over 10 yearsHi, I added a third point, which solves that issue for me. Regarding the above: "sys.stdout.encoding" probably does not know your terminal encoding, but only the system-wide encoding. If this is not equal to the terminal, then only parsing some environment variables may help. But that wont work always, as a terminal must not tell the other side its encoding. So the sending side can't ALWAYS know the encoding when it differs from the system.
-
Eryk Sun about 9 yearsPython 3:
sys.stdout = io.TextIOWrapper(sys.stdout.detach(), sys.stdout.encoding, 'replace'). Or use'backslashreplace'to preserve the ordinal value (but possibly misalign output formatting). -
jfs over 8 years@eryksun: or use
win-unicode-consolepackage to print Unicode directly whateverchcpis. Or setPYTHONIOENCODING=:replaceenvvar (outside your script). No need to change your script if it prints Unicode already, configure your environment instead. -
Eryk Sun over 8 years@J.F.Sebastian, I prefer the
win_unicode_consoleapproach over setting environment variables. It "just works". -
jfs over 8 years@eryksun: yes, but the envvar is useful if the output is redirected to a file/pipe.
-
Eryk Sun over 8 years@J.F.Sebastian, it was short-sighted for Python 3 to use the legacy ANSI codepage for a non-interactive standard stream. It's based on
locale.getpreferredencoding. Even in the latest VC 14 the locale implementation doesn't allow UTF-8 (e.g. forwcstombs); it's all legacy codepage based and should be avoided (IMO). Now it's too late to change the default encoding to UTF-8. This affects the subprocess module as well, since it's the default foruniversal_newlines=True. Hopefully Python 4 gets this right. -
Martijn Pieters over 7 yearsNow that Python 3.6 is out, perhaps include that as a recommendation too (as that version basically switched to the same solution as the
win-unicode-consolepackage). -
Martijn Pieters over 7 years@eryksun: and Python 3.6 corrects that now.
-
Eryk Sun over 7 years@MartijnPieters, 3.6 uses UTF-8 for bytes with os functions. I have a pending patch to extend this to
os.environb. UTF-8 is also used for thebufferandrawinterfaces for thesys.std*files, but only for the Windows console, i.e. when usingio.WindowsConsoleIO. If it's a file or pipe it still defaults to the legacy ANSI encoding. The same applies tosubprocess.Popen, but at least we now haveencodinganderrorsparameters. Steve Dower proposed to make UTF-8 the preferred encoding on Windows, but that wasn't implemented. Maybe in 3.8. -
Martijn Pieters over 7 years@eryksun: you should never rely on
locale.getpreferredencoding()for file I/O on any platform, that's not unique to Windows, and you can trivially set that to a proper codec explicitly. -
Martijn Pieters over 7 years@eryksun: I can sort of see the point of
encodingstill defaulting tolocale.getpreferredencoding()on Windows (like it does on any platform), because other tools still use that same setting when they are doing I/O. You'd need to fix the whole ecosystem; is Python in a position to dictate that direction on Windows? -
jfs over 7 years@MartijnPieters if you click the link then you see Python3.6 recommendation.
-
Martijn Pieters over 7 yearsAh, that makes a better dupe target then for the most recent post asking about Windows console printing behaviour.
-
Martijn Pieters over 7 yearsPity that that question uses screenshots for the output, however. That's next to useless for searching.
-
Eryk Sun over 7 years@MartijnPieters, for standard I/O you have to either set the
PYTHONIOENCODINGenvironment variable or rebindsys.std*. There's an open issue to allow changing the encoding of aTextIOWrapper, which will make this simpler.Popenshould continue to default to ANSI, and we also have the option to use OEM now. As to the preferred encoding, yes the issue with general ecosystem on Windows was what held up making that change. One idea that was proposed is a hybrid system that uses 'utf-8-sig' for new files and detects the BOM for existing files and otherwise uses ANSI. -
jfs over 7 years@MartijnPieters the canonical dupe target for "Windows console printing behavior" is in turn linked in the linked answer at the very top.
-
Martijn Pieters over 7 yearsI always search for a Python 3 specific one. I should drop
3and just search for the error message plus print, obviously. -
Martijn Pieters over 7 yearsAnd one of these days I'll find the energy to dupe close all the rest. Today is not that day.
-
khaled4vokalz about 7 yearsThis is not the issue here I think. I use 3.5.2 but getting the error.
-
Don Reba about 7 yearsoutputs: Antonín Dvo\u0159ák
-
Jelle Fresen about 7 yearsYes, that is the fallback if the output stream (e.g., your console) does not support the ř character: it will output the unicode code point in backslash notation: \uXXXX. You can substitute
'backslashreplace'with another preference if that suits your case better: docs.python.org/3.5/library/stdtypes.html#str.encode -
alvaro562003 almost 7 yearsencode('utf-8') was the good thing to do in my case. Thanks
-
Eryk Sun over 6 yearsThis is no good. The output is extremely buggy prior to Windows 8, and non-ASCII input fails up through Windows 10. Upgrading to Python 3.6 or installing
win_unicode_consoleis the way to get correct Unicode support in the Windows console. -
Eryk Sun over 6 years@khaled4vokalz, no, upgrading to Python 3.6 does solve this issue. We switched to using the Windows console's Unicode API in 3.6. There's no more legacy codepage headaches.
-
EMT almost 3 yearsThis information is not correct. I am using python 3.8 and still getting the error.
-
armyofda12mnkeys about 2 yearsI'm using python 3.10.4 and still getting the issue (use AWS CLI to get some international email templates)... I tried to export/set PYTHONIOENCODING=UTF-8 as some peeps rec but didn't work initially. However after a windows restart, That setting or this Beta Windows-10 UTF-8 setting seemed to work. stackoverflow.com/a/57134096/201156