When, if ever, is loop unrolling still useful?
Solution 1
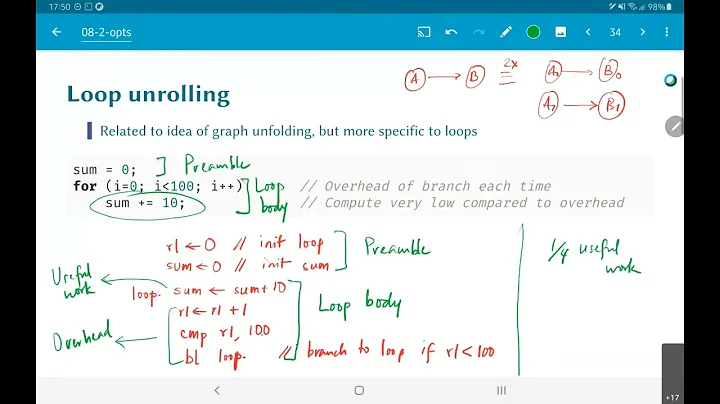
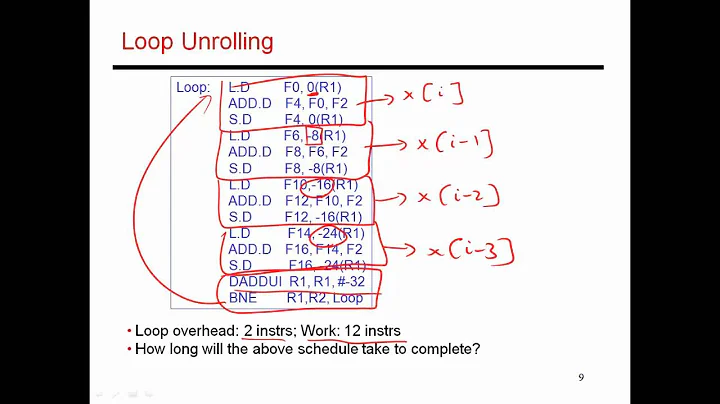
Loop unrolling makes sense if you can break dependency chains. This gives a out of order or super-scalar CPU the possibility to schedule things better and thus run faster.
A simple example:
for (int i=0; i<n; i++)
{
sum += data[i];
}
Here the dependency chain of the arguments is very short. If you get a stall because you have a cache-miss on the data-array the cpu cannot do anything but to wait.
On the other hand this code:
for (int i=0; i<n-3; i+=4) // note the n-3 bound for starting i + 0..3
{
sum1 += data[i+0];
sum2 += data[i+1];
sum3 += data[i+2];
sum4 += data[i+3];
}
sum = sum1 + sum2 + sum3 + sum4;
// if n%4 != 0, handle final 0..3 elements with a rolled up loop or whatever
could run faster. If you get a cache miss or other stall in one calculation there are still three other dependency chains that don't depend on the stall. A out of order CPU can execute these in parallel.
(See Why does mulss take only 3 cycles on Haswell, different from Agner's instruction tables? (Unrolling FP loops with multiple accumulators) for an in-depth look at how register-renaming helps CPUs find that parallelism, and an in depth look at the details for FP dot-product on modern x86-64 CPUs with their throughput vs. latency characteristics for pipelined floating-point SIMD FMA ALUs. Hiding latency of FP addition or FMA is a major benefit to multiple accumulators, since latencies are longer than integer but SIMD throughput is often similar.)
Solution 2
Those wouldn't make any difference because you're doing the same number of comparisons. Here's a better example. Instead of:
for (int i=0; i<200; i++) {
doStuff();
}
write:
for (int i=0; i<50; i++) {
doStuff();
doStuff();
doStuff();
doStuff();
}
Even then it almost certainly won't matter but you are now doing 50 comparisons instead of 200 (imagine the comparison is more complex).
Manual loop unrolling in general is largely an artifact of history however. It's another of the growing list of things that a good compiler will do for you when it matters. For example, most people don't bother to write x <<= 1 or x += x instead of x *= 2. You just write x *= 2 and the compiler will optimize it for you to whatever is best.
Basically there's increasingly less need to second-guess your compiler.
Solution 3
Regardless of branch prediction on modern hardware, most compilers do loop unrolling for you anyway.
It would be worthwhile finding out how much optimizations your compiler does for you.
I found Felix von Leitner's presentation very enlightening on the subject. I recommend you read it. Summary: Modern compilers are VERY clever, so hand optimizations are almost never effective.
Solution 4
As far as I understand it, modern compilers already unroll loops where appropriate - an example being gcc, if passed the optimisation flags it the manual says it will:
Unroll loops whose number of iterations can be determined at compile time or upon entry to the loop.
So, in practice it's likely that your compiler will do the trivial cases for you. It's up to you therefore to make sure that as many as possible of your loops are easy for the compiler to determine how many iterations will be needed.
Solution 5
Loop unrolling, whether it's hand unrolling or compiler unrolling, can often be counter-productive, particularly with more recent x86 CPUs (Core 2, Core i7). Bottom line: benchmark your code with and without loop unrolling on whatever CPUs you plan to deploy this code on.
Related videos on Youtube
 14 : 27
14 : 27
 04 : 24
04 : 24
 09 : 10
09 : 10
 04 : 32
04 : 32
 12 : 48
12 : 48
 01 : 52
01 : 52
 03 : 43
03 : 43
 17 : 49
17 : 49
dsimcha
Updated on February 26, 2022Comments
-
dsimcha about 2 years
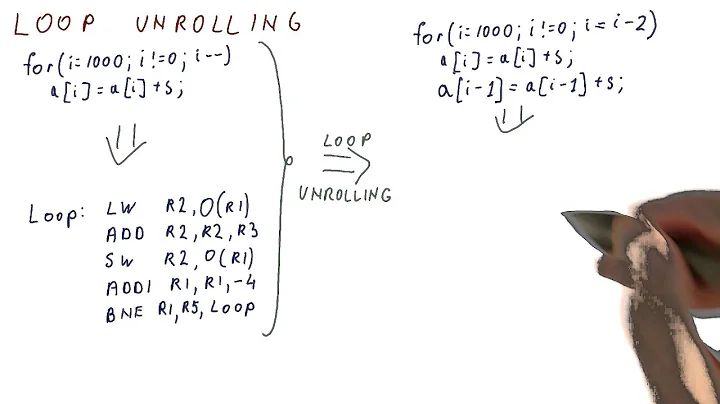
I've been trying to optimize some extremely performance-critical code (a quick sort algorithm that's being called millions and millions of times inside a monte carlo simulation) by loop unrolling. Here's the inner loop I'm trying to speed up:
// Search for elements to swap. while(myArray[++index1] < pivot) {} while(pivot < myArray[--index2]) {}I tried unrolling to something like:
while(true) { if(myArray[++index1] < pivot) break; if(myArray[++index1] < pivot) break; // More unrolling } while(true) { if(pivot < myArray[--index2]) break; if(pivot < myArray[--index2]) break; // More unrolling }This made absolutely no difference so I changed it back to the more readable form. I've had similar experiences other times I've tried loop unrolling. Given the quality of branch predictors on modern hardware, when, if ever, is loop unrolling still a useful optimization?
-
Peter Alexander about 14 yearsMay I ask why you aren't using standard library quicksort routines?
-
dsimcha about 14 years@Poita: Because mine have some extra features that I need for the statistical calculations I'm doing and are very highly tuned for my use cases and therefore less general but measurably faster than the standard lib. I'm using the D programming language, which has an old crappy optimizer, and for large arrays of random floats, I still beat GCC's C++ STL sort by 10-20%.
-
-
dsimcha about 14 yearsI was unrolling a quick sort that gets called from the inner loop of my simulation, not the main loop of the simulation.
-
fastcodejava about 14 yearsI agree, those days are over where you can tweak some loop here and there and expect huge benefit. Compilers are so advanced.
-
 Mike Dunlavey about 14 yearsI like it when the compiler optimizes
Mike Dunlavey about 14 yearsI like it when the compiler optimizesx *= 2for me. I don't like it when it tries to reorganize my code. That includes loop unrolling, code lifting, eliding code that it thinks will never be reached, stuff like that. I'm perfectly capable of deciding when or when not to do those things. -
dmckee --- ex-moderator kitten about 14 years@Mike Certainly turning optimization off if a good idea when puzzled, but it is worth reading the link that Poita_ posted. Compilers are getting painfully good at that business.
-
Mike Dunlavey about 14 years@dmckee: I read it. They're getting painfully good at navel-gazing. There's what real optimization is about: stackoverflow.com/questions/926266/…
-
dsimcha about 14 yearsThanks. I've tried loop unrolling in this style in several other places in the library where I'm calculating sums and stuff, and in these places it works wonders. I'm almost sure the reason is that it increases instruction level parallelism, as you suggest.
-
Mr. Boy about 14 years@Mike "I'm perfectly capable of deciding when or when not to do those things"... I doubt it, unless you're superhuman.
-
Mike Dunlavey about 14 years@John: I don't know why you say that; folks seem to think optimization is some kind of black art only compilers and good guessers know how to do. It all comes down to instructions and cycles and the reasons why they are spent. As I've explained many times on SO, it is easy to tell how and why those are being spent. If I've got a loop that has to use a significant percent of time, and it spends too many cycles in the loop overhead, compared to the content, I can see that and unroll it. Same for code hoisting. It doesn't take a genius.
-
Mr. Boy about 14 yearsI'm sure it's not that hard, but I still doubt you can do it as fast as the compiler does. What's the problem with the compiler doing it for you anyway? If you don't like it just turn optimizations off and burn your time away like it's 1990!
-
Mike Dunlavey about 14 years@John: Hey, why 1990? There's a relay computer that runs around 5 hz :-) Now that's when you really count cycles! Anyone who's spent many years writing assembler, as I have, is happy to have a compiler managing registers and optimizing simple stuff as well or better than they could. But scrambling code? in a way that confuses the debugger but usually doesn't help? They're doing it because they can and it's fun, and because one of the myths of performance is that it makes a significant difference.
-
Mike Dunlavey about 14 yearsThat is a good read, but the only part I thought was on the mark was where he talks about keeping data structure simple. The rest of it was accurate but rests on a giant unstated assumption - that what is being executed has to be. In the tuning I do, I find people worrying about registers & cache misses when massive amounts of time are going into needless mountains of abstraction code.
-
 JohnTortugo over 10 yearsWhy particularly on recet x86 CPUs?
JohnTortugo over 10 yearsWhy particularly on recet x86 CPUs? -
Paul R over 10 years@JohnTortugo: Modern x86 CPUs have certain optimisations for small loops - see e.g. Loop Stream Detector on Core and Nehalem achitectures - unrolling a loop so that it is no longer small enough to fit within the LSD cache defeats this optimisation. See e.g. tomshardware.com/reviews/Intel-i7-nehalem-cpu,2041-3.html
-
Toby Brull over 9 yearsNice answer and instructive example. Although I do not see how stalls on cache-misses could impact performance for this particular example. I came to explain to myself the performance differences between the two pieces of code (on my machine the second piece of code is 2-3 times faster) by noting that the first disables any kind of instruction-level parallelism in the floating point lanes. The second would allow a super-scalar CPU to execute up to four floating point adds at the same time.
-
bobbogo almost 9 yearsThe performance gain due to loop unrolling has nothing to do with the comparisons that you are saving. Nothing at all.
-
 Bas almost 8 yearsKeep in mind that the result will not be numerically identical to the original loop when computing a sum this way.
Bas almost 8 yearsKeep in mind that the result will not be numerically identical to the original loop when computing a sum this way. -
 Veedrac almost 7 yearsThe loop-carried dependency is one cycle, the addition. An OoO core will do fine. Here unrolling might help floating point SIMD, but that isn't about OoO.
Veedrac almost 7 yearsThe loop-carried dependency is one cycle, the addition. An OoO core will do fine. Here unrolling might help floating point SIMD, but that isn't about OoO. -
Veedrac almost 7 years"hand optimizations are almost never effective" → Perhaps true if you're completely new to the task. Simply not true otherwise.
-
 Aisah Hamzah over 6 yearsJust in time compilers usually don't do loop unrolling, the heuristics are too expensive. Static compilers can spend more time on it, but the difference between the two dominant ways is important.
Aisah Hamzah over 6 yearsJust in time compilers usually don't do loop unrolling, the heuristics are too expensive. Static compilers can spend more time on it, but the difference between the two dominant ways is important. -
 Peter Cordes about 6 years@Veedrac: The loop counter is integer, the other types are unknown. FP would be the best example: (3 or 4c latency), and the compiler can't unroll with multiple accumulators (or even auto-vectorize) for you unless you use
Peter Cordes about 6 years@Veedrac: The loop counter is integer, the other types are unknown. FP would be the best example: (3 or 4c latency), and the compiler can't unroll with multiple accumulators (or even auto-vectorize) for you unless you use-ffast-mathor OpenMP. But even with integer, x86 CPUs can do 2 loads per clock from L1d, so with loop unrolling to reduce overhead + multiple accumulators to hide the 1c latency, you can do 2 vectors of SIMD additions per clock on Sandybridge-family or AMD since K8. The data may have to be hot in L1d to avoid a bottleneck, and loop overhead needs to be minimized... -
Veedrac about 6 years@PeterCordes I agree with what you're saying. My issue is that this wasn't what the answer is saying; it's not talking about ILP or FP latency or SIMD. It's talking about scheduling around cache misses.
-
Peter Cordes about 6 years@Veedrac: oh! I just read it again, yeah, right code wrong reason. Except that the stalled dep chain can "catch up" faster once the stalled load finishes. But that's minor.
-
Nils Pipenbrinck about 6 yearsfolks, the answer is 8 years old now. Things might have changed in the meantime :-)
-
Peter Cordes about 6 years@Nils: Not very much; mainstream x86 OoO CPUs are still similar enough to Core2/Nehalem/K10. Catching up after a cache miss was still pretty minor, hiding FP latency was still the major benefit. In 2010, CPUs that could do 2 loads per clock were even rarer (just AMD because SnB wasn't released yet), so multiple accumulators were definitely less valuable for integer code than now (of course this is scalar code that should auto-vectorize, so who knows whether compilers will turn multiple accumulators into vector elements or into multiple vector accumulators...)
-
WDUK over 4 yearsIn 2019 I've still done manual unrolls with substantial gains over the compiler's auto attempts.. so its not that reliable to let the compiler do it all. It seems to not unroll all that often. At least for c# i can't speak on behalf of all languages.