Where do I find core dump files, and how do I view and analyze the backtrace (stack trace) in one?
Solution 1
Tested in Ubuntu 20.04.
1. Enable core files
First off, run ulimit -c to see what the max allowed size is for core files on your system. On Ubuntu 20.04 for me, mine returns 0, which means no core file can be created.
ulimit --help shows the meaning of -c:
-c the maximum size of core files created
So, set the allowed core file size to unlimited, as shown below. Note that I think this only applies to the one terminal you run this in, and I do not think it's persistent across reboots, so you have to run this each time you want core files to be created, and in each terminal you want it to work in:
# set max core dump file size to unlimited
ulimit -c unlimited
# verify it is now set to "unlimited"
ulimit -c
That's it! Now, run your program and if it crashes and does a "core dump" it will dump the core as a core file into the same directory you were in when you called the executable. The name of the file is simply "core".
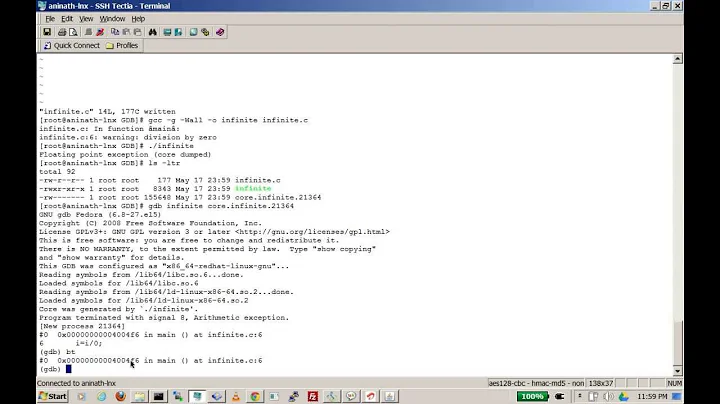
2. View the backtrace in gdb
You should have built your C or C++ program with debug symbols on, in order to see useful information in your core file. Without debug symbols, you can only see the addresses of the functions called, not the actual names or line numbers.
In gcc, use -ggdb -O0 to turn on debug symbols optimized for the gdb GNU debugger. You can also use -g -O0, -g3 -O0, etc, but -ggdb -O0 is best. Do we really need optimization level 0 (-O0) for this? Yes, yes we do. See my answer here: Stack Overflow: What's the difference between a compiler's -O0 option and -Og option?
Example build and run commands in C and C++: so, your full build and run commands in C or C++ might look like this:
# C build and run command for "hello_world.c"
gcc -Wall -Wextra -Werror -ggdb -O0 -std=c11 -o hello_world hello_world.c \
&& ./hello_world
# C++ build and run command for "hello_world.c"
g++ -Wall -Wextra -Werror -ggdb -O0 -std=c++17 -o hello_world hello_world.c \
&& ./hello_world
Open the core file in gdb like this:
gdb path/to/my/executable path/to/core
Assuming you just ran path/to/my/executable, then the core file will be in the same directory you were just in when the core was dumped, so you can just run this:
gdb path/to/my/executable core
In gdb, view the backtrace (function call stack at the time of the crash) with:
bt
# or (exact same command)
where
# OR (for even more details, such as seeing all arguments to the functions--
# thanks to Peter Cordes in the comments below)
bt full
# For gdb help and details, see:
help bt
# or
help where
IMPORTANT: when a core dump occurs, it does NOT automatically overwrite any pre-existing core file in your current directory with a new one, so you must manually remove the old core file with rm core PRIOR TO generating the new core file when your program crashes, in order to always have the latest core file to analyze.
3. Try it out
- In a terminal, run
sleep 30to start a process sleeping for 30 seconds. - While it is running, press Ctrl + \ to force a core dump. You'll now see a
corefile in the directory you are in. - Since we don't have an executable for this with debugging symbols in it, we will just open up the core file in gdb instead of the executable file with symbols + the core file. So, run
gdb -c coreto open the core file just created by the forced crash. - You'll see this. Notice it knows what command you called (
sleep 30) when the core dump occurred:Core was generated by `sleep 30'. Program terminated with signal SIGQUIT, Quit. #0 0x00007f93ed32d334 in ?? () (gdb) - Run
btorwhereto see the backtrace. You'll see this:(gdb) bt #0 0x00007f93ed32d334 in ?? () #1 0x000000000000000a in ?? () #2 0x00007f93ed2960a5 in ?? () #3 0x0000000000000000 in ?? () (gdb) - Those are the addresses to the functions called on the call stack. If you had debugging symbols on, you'd see a lot more info, including function names and line numbers, like this (pulled from a C program of mine):
#10 0x00007fc1152b8ebf in __printf (format=<optimized out>) at printf.c:33 #11 0x0000562bca17b3eb in fast_malloc (num_bytes=1024) at src/fast_malloc.c:225 #12 0x0000562bca17bb66 in malloc (num_bytes=1024) at src/fast_malloc.c:496
4. Forget about core files and just run the program to the crash point in gdb directly!
As @Peter Cordes states in the comments below, you can also just run the program inside gdb directly, letting it crash there, so you have no need to open up a core file after-the-fact! He stated:
Those GDB commands are not specific to core files, they work any time you're stopped at a breakpoint. If you have a reproducible crash, it's often easier / better to run your program under GDB (like
gdb ./a.out) so GDB will have the process in memory instead of a core file. The main advantage is that you can set a breakpoint or watchpoint somewhere before the thing that crashed, and single-step to see what's happening. Or with GDB's record facilities, you may be able to step backwards and see what led up to the crash, but that can be flaky, slow, and memory-intensive.
As stated above, you should have compiled your program with debugging symbols on and with Optimization Level 0, using -ggdb -O0. See the full example build and run commands in C and C++ above.
Now run the program in gdb:
# Open the executable in gdb
gdb path/to/my/executable
# Run it (if it's still crashing, you'll see it crash)
r
# View the backtrace (call stack)
bt
# Quit when done
q
And if you ever need to manually log the backtrace to a log file to analyze later, you can do so like this (adapted from notes in my eRCaGuy_dotfiles repo here):
set logging file gdb_log.txt
set logging on
set trace-commands on
show logging # prove logging is on
flush
set pretty print on
bt # view the backtrace
set logging off
show logging # prove logging is back off
Done! You've now saved the gdb backtrace in file "gdb_log.txt".
References:
- [the answer I needed is in this question itself] https://stackoverflow.com/questions/2065912/core-dumped-but-core-file-is-not-in-the-current-directory
- https://stackoverflow.com/questions/5115613/core-dump-file-analysis
- https://stackoverflow.com/questions/8305866/how-do-i-analyze-a-programs-core-dump-file-with-gdb-when-it-has-command-line-pa/30524347#30524347
- [very useful info, incl. the Ctrl + \ trick to force a core dump!] https://unix.stackexchange.com/questions/277331/segmentation-fault-core-dumped-to-where-what-is-it-and-why/409776#409776
- [referenced by the answer above] https://unix.stackexchange.com/questions/179998/where-to-search-for-the-core-file-generated-by-the-crash-of-a-linux-application/180004#180004
- [answer is in the question itself] Where do I find the core dump in ubuntu 16.04LTS?
- [my answer] Stack Overflow: What's the difference between a compiler's
-O0option and-Ogoption?
Additional reading to do
- [I STILL NEED TO STUDY & TRY THIS] How to use
LD_PRELOADwithgdb: https://stackoverflow.com/questions/10448254/how-to-use-gdb-with-ld-preload
Solution 2
Found via search. I'm running Ubuntu Mate 21.10. For those running late model Ubuntu, apport will generate dumps in /var/lib/apport/coredump.
If you can't find your core dump file, cat /var/log/apport.log. When I did that, I saw:
executable does not belong to a package, ignoring
called for pid 5545, signal 11, core limit 0, dump mode 1
Notice the core limit 0, that means no core dump file will be generated. So, I ran the command shown in this post (ulimit -c unlimited), and this time apport.log showed this:
writing core dump to core._my_prog.1000.e43b2f33-4708-438c-a7d7-05062f381382.5650.795448 (limit: -1)
I couldn't find this in the current directory or the directory containing the executable, so I did a find on the entire system and found it in /var/lib/apport/coredump.
Related videos on Youtube
 01 : 27
01 : 27
 01 : 22 : 01
01 : 22 : 01
 09 : 16
09 : 16
 05 : 44
05 : 44
 12 : 42
12 : 42
Gabriel Staples
Updated on September 18, 2022Comments
-
Gabriel Staples over 1 year
When I run my C program on Ubuntu 20.04, I get this run-time error:
Segmentation fault (core dumped)I really need to find and view the
corefile, but I can't find it anywhere. Where is it, and how do I view the backtrace in it? -
 Peter Cordes almost 3 yearsIf you have debug symbols,
Peter Cordes almost 3 yearsIf you have debug symbols,bt fullis nice: shows args and stuff. Or eventhread apply all bt fullfor a multithreaded program. (Although that's more than you'd normally want to look at all at once, so it's useful for sending a bug report moreso than for your own use.) -
Gabriel Staples almost 3 years@PeterCordes, thanks. I added a note about
bt fullnow in the answer too. I'm brand new to looking at core dumps. Writing this answer yesterday was both my first time ever seeing acorefile and my first time ever doing a backtrace on one. -
Peter Cordes almost 3 yearsThose GDB commands are not specific to core files, they work any time you're stopped at a breakpoint. If you have a reproducible crash, it's often easier / better to run your program under GDB (like
gdb ./a.out) so GDB will have the process in memory instead of a core file. The main advantage is that you can set a breakpoint or watchpoint somewhere before the thing that crashed, and single-step to see what's happening. Or with GDB's record facilities, you may be able to step backwards and see what led up to the crash, but that can be flaky, slow, and memory-intensive. -
 Admin almost 2 yearsI found that core dumps are saved to
Admin almost 2 yearsI found that core dumps are saved to/var/lib/apport/coredumpon Ubuntu 20.04 as well at this date, despite others having different experience.