Why am I seeing retransmissions across the network using iperf3?
Solution 1
It appears that something (NIC or kernel?) is slowing down traffic when its being output to the bond0 interface. In the linux bridge (pod) case, the "NIC" is simply a veth which (when I tested mine) hit a peak around 47Gbps. So when iperf3 is asked to send packets out the bond0 interface, it overruns the interface and ends up with dropped packets (unclear why we see drops on the receiving host).
I confirmed that if I apply a tc qdisc class to slow down the pod interface to 10gbps, there is no loss when simply running iperf3 to the other pod.
tc qdisc add dev eth0 root handle 1:0 htb default 10
tc class add dev eth0 parent 1:0 classid 1:10 htb rate 10Gbit
This was enough to ensure that an iperf3 run without a bandwidth setting didn't incur retransmissions due to overrunning the NIC. I'll be looking for a way to slow down flows that would egress the NIC with tc.
update: Here's how to slow down traffic for everything but the local bridged subnet.
tc qdisc add dev eth0 root handle 1:0 htb default 10
tc class add dev eth0 classid 1:5 htb rate 80Gbit
tc class add dev eth0 classid 1:10 htb rate 10Gbit
tc filter add dev eth0 parent 1:0 protocol ip u32 match ip dst 10.81.18.4/24 classid 1:5
Solution 2
author of kube-router here. Kube-router relies on Bridge CNI plug-in to create kube-bridge. Its standard linux networking nothing specifically tuned for pod networking. kube-bridge is set to default value which is 1500. We have a open bug to set to some sensible value.
https://github.com/cloudnativelabs/kube-router/issues/165
Do you think errors seen are due to less MTU?
Related videos on Youtube
 10 : 16
10 : 16
 09 : 26
09 : 26
 03 : 09
03 : 09
 12 : 10
12 : 10
 08 : 08
08 : 08
dlamotte
Updated on September 18, 2022Comments
-
dlamotte over 1 year
I'm seeing retransmissions between two pods in a kubernetes cluster I'm setting up. I'm using kube-router https://github.com/cloudnativelabs/kube-router for the networking between the hosts. Here's the setup:
host-a and host-b are connected to the same switches. They are on the same L2 network. Both are connected to the above switches with LACP 802.3ad bonds and those bonds are up and functioning properly.
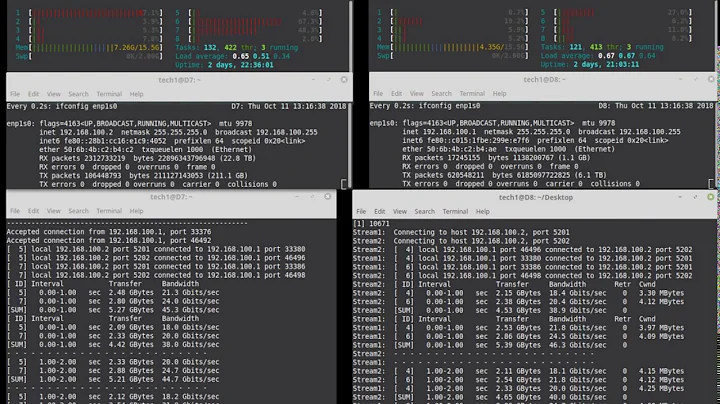
pod-a and pod-b are on host-a and host-b respectively. I'm running iperf3 between the pods and see retransmissions.
root@pod-b:~# iperf3 -c 10.1.1.4 Connecting to host 10.1.1.4, port 5201 [ 4] local 10.1.2.5 port 55482 connected to 10.1.1.4 port 5201 [ ID] Interval Transfer Bandwidth Retr Cwnd [ 4] 0.00-1.00 sec 1.15 GBytes 9.86 Gbits/sec 977 3.03 MBytes [ 4] 1.00-2.00 sec 1.15 GBytes 9.89 Gbits/sec 189 3.03 MBytes [ 4] 2.00-3.00 sec 1.15 GBytes 9.90 Gbits/sec 37 3.03 MBytes [ 4] 3.00-4.00 sec 1.15 GBytes 9.89 Gbits/sec 181 3.03 MBytes [ 4] 4.00-5.00 sec 1.15 GBytes 9.90 Gbits/sec 0 3.03 MBytes [ 4] 5.00-6.00 sec 1.15 GBytes 9.90 Gbits/sec 0 3.03 MBytes [ 4] 6.00-7.00 sec 1.15 GBytes 9.88 Gbits/sec 305 3.03 MBytes [ 4] 7.00-8.00 sec 1.15 GBytes 9.90 Gbits/sec 15 3.03 MBytes [ 4] 8.00-9.00 sec 1.15 GBytes 9.89 Gbits/sec 126 3.03 MBytes [ 4] 9.00-10.00 sec 1.15 GBytes 9.86 Gbits/sec 518 2.88 MBytes - - - - - - - - - - - - - - - - - - - - - - - - - [ ID] Interval Transfer Bandwidth Retr [ 4] 0.00-10.00 sec 11.5 GBytes 9.89 Gbits/sec 2348 sender [ 4] 0.00-10.00 sec 11.5 GBytes 9.88 Gbits/sec receiver iperf Done.The catch here that I'm trying to debug is that I don't see retransmissions when I run the same iperf3 across host-a and host-b directly (not over the bridge interface that kube-router creates). So, the network path looks something like this:
pod-a -> kube-bridge -> host-a -> L2 switch -> host-b -> kube-bridge -> pod-bRemoving the kube-bridge from the equation results in zero retransmissions. I have tested host-a to pod-b and seen the same retransmissions.
I have been running dropwatch and seeing the following on the receiving host (the iperf3 server by default):
% dropwatch -l kas Initalizing kallsyms db dropwatch> start Enabling monitoring... Kernel monitoring activated. Issue Ctrl-C to stop monitoring 2 drops at ip_rcv_finish+1f3 (0xffffffff87522253) 1 drops at sk_stream_kill_queues+48 (0xffffffff874ccb98) 1 drops at __brk_limit+35f81ba4 (0xffffffffc0761ba4) 16991 drops at skb_release_data+9e (0xffffffff874c6a4e) 1 drops at tcp_v4_do_rcv+87 (0xffffffff87547ef7) 1 drops at sk_stream_kill_queues+48 (0xffffffff874ccb98) 2 drops at ip_rcv_finish+1f3 (0xffffffff87522253) 1 drops at sk_stream_kill_queues+48 (0xffffffff874ccb98) 3 drops at skb_release_data+9e (0xffffffff874c6a4e) 1 drops at sk_stream_kill_queues+48 (0xffffffff874ccb98) 16091 drops at skb_release_data+9e (0xffffffff874c6a4e) 1 drops at __brk_limit+35f81ba4 (0xffffffffc0761ba4) 1 drops at tcp_v4_do_rcv+87 (0xffffffff87547ef7) 1 drops at sk_stream_kill_queues+48 (0xffffffff874ccb98) 2 drops at skb_release_data+9e (0xffffffff874c6a4e) 8463 drops at skb_release_data+9e (0xffffffff874c6a4e) 2 drops at skb_release_data+9e (0xffffffff874c6a4e) 2 drops at skb_release_data+9e (0xffffffff874c6a4e) 2 drops at tcp_v4_do_rcv+87 (0xffffffff87547ef7) 2 drops at ip_rcv_finish+1f3 (0xffffffff87522253) 2 drops at skb_release_data+9e (0xffffffff874c6a4e) 15857 drops at skb_release_data+9e (0xffffffff874c6a4e) 1 drops at sk_stream_kill_queues+48 (0xffffffff874ccb98) 1 drops at __brk_limit+35f81ba4 (0xffffffffc0761ba4) 7111 drops at skb_release_data+9e (0xffffffff874c6a4e) 9037 drops at skb_release_data+9e (0xffffffff874c6a4e)The sending side sees drops, but nothing in the amounts we are seeing here (1-2 max per line of output; which I hope is normal).
Also, I'm using 9000 MTU (on the bond0 interface to the switch and on the bridge).
I'm running CoreOS Container Linux Stable 1632.3.0. Linux hostname 4.14.19-coreos #1 SMP Wed Feb 14 03:18:05 UTC 2018 x86_64 GNU/Linux
Any help or pointers would be much appreciated.
update: tried with 1500 MTU, same result. Significant retransmissions.
update2: appears that
iperf3 -b 10G ...yields no issues between pods and directly on host (2x 10Gbit NIC in LACP Bond). The issues arise when usingiperf3 -b 11Gbetween pods but not between hosts. Is iperf3 being smart about the NIC size but can't on the local bridged veth? -
dlamotte about 6 yearsSee my first update in the original question and my answer as well, I have changed the default from 1500 MTU to 9000 MTU. I tested both 1500 and 9000 MTU both with the same result. At this point, I'm not sure what networking provider actually fixes the underlying problem. I think the problem is the pod's interface is "too fast" on the bridge network which isn't unique to kube-router if I had to guess.
-
 fixer1234 over 5 yearsWelcome to Super User. It isn't clear how this answers the question. The site is a knowledge base of solutions and relies on answers being solutions to what was asked in the question. General discussion that might be helpful, but tangential, like the first paragraph, can be posted in a comment with a little more rep. The second paragraph, about your own experience, might be something that could go in a new question, if you are seeking an answer, but is discouraged in our Q&A format.
fixer1234 over 5 yearsWelcome to Super User. It isn't clear how this answers the question. The site is a knowledge base of solutions and relies on answers being solutions to what was asked in the question. General discussion that might be helpful, but tangential, like the first paragraph, can be posted in a comment with a little more rep. The second paragraph, about your own experience, might be something that could go in a new question, if you are seeking an answer, but is discouraged in our Q&A format.