Detect Character encoding of unknown characters in Notepad++, and find/replace
The black characters are caused by Notepad++ not being able to map those byte sequences to a UTF-8 endpoint that can be visualized. As you might know, each character is stored as a series of bytes. In this case, those bytes are
In Hexadecimal
ED A0 BD ED B8 8A
In Binary
1110 1101 1010 0000 1011 1101 1110 1101 1011 1000 1000 1010
This brings us to your questions.
What is the encoding of those black characters?
These are two UTF-8 characters. More specifically, the first one ED A0 BD is what is called a 'high surrogate' the second one ED B8 8A is a 'low surrogate'. Together, they form an UCS surrogate. Now that we know these are surrogate characters, we can reverse the surrogate pair calculation.
If you look up these byte sequences in the UTF-8 code-points table, you will find that the first one maps to U+D83D and the second one maps to U+DE0A. Hence, the pair is D83D+DE0A. This maps to U+1F60A, which is..... drumroll A smiley!
So, the sequence you are looking at... is a smiley.
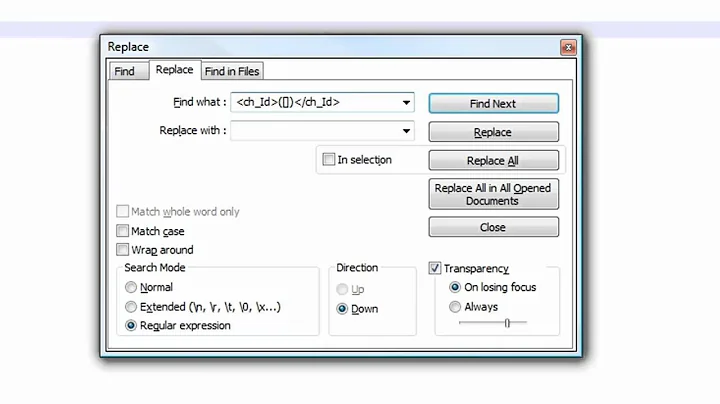
A regular expression to find these characters
Now that we know this, we can use regex to find sequences like this like so:
\x{D83D}\x{DE0A}
And then for the question that you added in the comments later (this is an edit).
is there any other utility I can find the characters which are not in UTF8 in my csv file.
I have shown now that the characters in your file are UTF-8. However, to still answer your question, if you want a tool to manually try and find the encoding of some characters, you can use this website. Here you can enter some text, specify the encoding, and transform it into another encoding to see what characters it maps to.
Related videos on Youtube
 17 : 18
17 : 18
 02 : 56
02 : 56
 02 : 41
02 : 41
 08 : 42
08 : 42
 09 : 40
09 : 40
 04 : 42
04 : 42
 08 : 23
08 : 23
user2068804
Updated on September 18, 2022Comments
-
user2068804 over 1 year
I have a CSV file in which I can see the following excerpt:

I found these "black" characters by scrolling through the file. The file is huge(32 Mb). I am not sure what encoding the file is in; At the moment my Notepad++ is set to "Encode in UTF-8". Also, when I try to do ASCII -> HEX (Plugins->Converter->ASCII -> HEX), I get the following output:
EDA0BDEDB88AI would like to know:
- The encoding of these black characters.
- A regular expression to find similar occurrences inside my CSV file
-
user2068804 almost 7 yearsis there any other utility I can find the characters which are not in UTF8 in my csv file. Kindly let me know
-
Wouter almost 7 yearsI figured it out! :) Check out my edit. The sequence you are looking at is a smiley! Problem solved. Case closed.