Extract paragraph separated with *** using AWK
Solution 1
Tell awk to print between the two delimiters. Specifically:
awk '/\*{4,}/,/<np>/' file
That will also print the lines containing the delimiters, so you can remove them with:
awk '/\*{4,}/,/<np>/' file | tail -n +2 | head -n -1
Alternatively, you can set a variable to true if a line matches the 1st delimiter and to false when it matches the second and only print when it is true:
awk '/\*{4,}/{a=1; next}/<np>/{a=0}(a==1){print}' file
The command above will set a to 1 if the current line matches 4 or more * and will also skip to the next line. This means that the *** line will never be printed.
This was in answer to the original, misunderstood, version of the question. I'm leaving it here since it can be useful in a slightly different situation.
First of all, you don't want FS (field separator), you want RS (record separator). Then, to pass a literal *, you need to escape it twice. Once to escape the * and once to escape the backslash (otherwise, awk will try to match it in the same way as \r or \t). Then, you print the 2nd "line":
$ awk -vRS='\\*\\*\\*' 'NR==2' file
thingsIwantToRead1
thingsIwantToRead2
thingsIwantToRead3
To avoid the blank lines around the output, use:
$ awk -vRS='\n\\*\\*\\*\n' 'NR==2' file
thingsIwantToRead1
thingsIwantToRead2
thingsIwantToRead3
Note that this assumes a *** after each paragraph, not only after the first one as you show.
Solution 2
In addition to @terdon's answer, with awk (and sed) you can use range pattern:
awk '/sep1/,/sep2/{print}' file
or
sed -n '/sep1/,/sep2/p' file
will print everything (including) sep1 and sep2. That is:
~$ awk '/sep1/,/sep2/{print}' file
sep1
thingsIwantToRead1
thingsIwantToRead2
thingsIwantToRead3
sep2
In your case:
~$ awk '/\*\*\*/,/^$/{print}' file
***
thingsIwantToRead1
thingsIwantToRead2
thingsIwantToRead3
Then you might want to delete the first and last line.
For instance with:
~$ sed -n '/\*\*\*/,/^$/p' file | sed '1d;$d'
thingsIwantToRead1
thingsIwantToRead2
thingsIwantToRead3
or
~$ awk '/\*\*\*/,/^$/{print}' file | awk 'NR>1&&!/^$/ {print}'
thingsIwantToRead1
thingsIwantToRead2
thingsIwantToRead3
If your paragraph isn't too long.
Solution 3
With sed there are two ways to go with this. You can select inclusively or exclusively. In your case, an inclusive selection means printing all lines beginning with a match for '^*\*\*' up to and including one of either ^ *<np> (whatever that is) or ^$ a blank line.
An inclusive selection can be specified with any of the range expressions demonstrated in the other answers and involves specifying a start printing here pattern through to a all the way through here pattern.
An exclusive selection works in the opposite way. It specifies a stop printing before here pattern through to a start printing after here pattern. For your example data - and allowing for a stop printing before here pattern which will match either of a blank-line or that <np> thing:
sed -e 'x;/^\( *<np>.*\)*$/,/^*\** *$/c\' -e '' <infile >outfile
x- Swaps hold and pattern spaces. This institutes a look-behind -
sedis always one-line behind input - and the first line is always blank.
- Swaps hold and pattern spaces. This institutes a look-behind -
/^\( *<np>.*\)*$/- This selects a stop printing before here line that matches from head to tail zero or more occurrences in the match group. Two kinds of lines can match zero or more occurrences of that - either a blank line or one with any number of <spaces> at the head of the line followed by the string
<np>.
- This selects a stop printing before here line that matches from head to tail zero or more occurrences in the match group. Two kinds of lines can match zero or more occurrences of that - either a blank line or one with any number of <spaces> at the head of the line followed by the string
/^*\** *$/- This selects a start printing after here line which opens with at least one
*asterisk character and continues to the end of the line with only zero or more occurrences of the*asterisk and possibly closed by any number of spaces.
- This selects a start printing after here line which opens with at least one
c\' -e ''- This
changes the entire blocked selection to a single blank line, squeezing all unwanted lines to the stringEOF.
- This
So any number of lines occurring before ^*\** *$ and after the first following ^\( *<np>.*\)*$ are always squeezed down to only a single blank, and only the first occurring paragraph after a match for ^*\** *$ is printed to stdout. It prints...
2012/10/01 00:00:00.000 6998.239 0.001233 97.95558 77.41733 89.98551 290.75808 359.93398 2012/10/01 00:05:00.000 6993.163 0.001168 97.95869 77.41920 124.72698 274.57362 359.93327 2012/10/01 00:10:00.000 6987.347 0.001004 97.96219 77.42327 170.94020 246.92395 359.94706 2012/10/01 00:15:00.000 6983.173 0.000893 97.96468 77.42930 224.76158 211.67042 359.97311
That assumes you want to handle any number of occurrences of the paragraph pattern in input. If you only want the first however, provided you have GNU grep and that infile is a regular, lseekable file:
{ grep -xm1 '*\** *' >&2
sed -n '/^\( *<np>.*\)*$/q;p'
} <infile 2>/dev/null >outfile
... will work as well.
And actually, I guess, there are three ways. The third might look like:
sed 'H;$!d;x;s/\(\n\*\** *\n\(\([0-9./: ]*\n\)*\)\)*./\2/g'
...which reads in the whole file and then globally substitutes away every character which doesn't fall within the specifications of the matched lines. It prints the same as before, but those are a pain to write, and they're only safe performance-wise when you balance the optionals against any character.
Solution 4
Updated version based on question's edit:
Using Perl:
< inputfile perl -0777 -pe 's/.*[*]+\n(.*) <np>\n.*/$1/s' > outputfile
< inputfile: redirects the content ofinputfiletoperl'sstdin-0777: forces Perl to slurp the whole file at once instead of line by line-p: forces Perl to print the lines-e: forces Perl to read a line of program from the arguments> outputfile: redirects the content ofperl'sstdouttooutputfile
Regex breakdown:
s: asserts to perform a substitution/: starts the search pattern.*[*]+\n: matches any number of any character up to the end of a string ending with one or more*character immediately followed by a newline character(.*) <np>: matches and groups any number of any character up to any character immediately followed by a<np>\nstring.*: matches any number of any character/: stops the search pattern / starts the replace pattern$1: replaces with the captured group/: stops the replace pattern / starts the modifierss: asserts to treat the input string as a single line, forcing.to also match newline characters
Sample output:
~/tmp$ cat inputfile
13.2000000000 , 3*0.00000000000 , 11.6500000000 , 3*0.00000000000 , 17.8800000000
Blablabla
SATELLITE EPHEMERIS
===================
Output frame: Mean of J2000
Epoch A E I RA AofP TA Flight Ang
*****************************************************************************************************************
2012/10/01 00:00:00.000 6998.239 0.001233 97.95558 77.41733 89.98551 290.75808 359.93398
2012/10/01 00:05:00.000 6993.163 0.001168 97.95869 77.41920 124.72698 274.57362 359.93327
2012/10/01 00:10:00.000 6987.347 0.001004 97.96219 77.42327 170.94020 246.92395 359.94706
2012/10/01 00:15:00.000 6983.173 0.000893 97.96468 77.42930 224.76158 211.67042 359.97311
<np>
----------------
Predicted Orbit:
----------------
Blablabla
~/tmp$ < inputfile perl -0777 -pe 's/.*[*]+\n(.*) <np>\n.*/$1/s'
2012/10/01 00:00:00.000 6998.239 0.001233 97.95558 77.41733 89.98551 290.75808 359.93398
2012/10/01 00:05:00.000 6993.163 0.001168 97.95869 77.41920 124.72698 274.57362 359.93327
2012/10/01 00:10:00.000 6987.347 0.001004 97.96219 77.42327 170.94020 246.92395 359.94706
2012/10/01 00:15:00.000 6983.173 0.000893 97.96468 77.42930 224.76158 211.67042 359.97311
~/tmp$
Original version:
Using Perl:
< inputfile perl -0777 -pe 's/.*[*]{3}\n(.*\n)\n.*/$1/s' > outputfile
< inputfile: redirects the content ofinputfiletoperl'sstdin-0777: forces Perl to slurp the whole file at once instead of line by line-p: forces Perl to print the lines-e: forces Perl to read a line of program from the arguments> outputfile: redirects the content ofperl'sstdouttooutputfile
Regex breakdown:
s: asserts to perform a substitution/: starts the search pattern.*[*]{3}\n: matches any number of any character up to the end of a***\nstring(.*\n)\n: matches and groups any number of any character up to a newline character immediately followed by a newline character.*: matches any number of any character/: stops the search pattern / starts the replace pattern$1: replaces with the captured group/: stops the replace pattern / starts the modifierss: asserts to treat the input string as a single line, forcing.to also match newline characters
Sample output:
~/tmp$ cat inputfile
blablabla
blablabla
***
thingsIwantToRead1
thingsIwantToRead2
thingsIwantToRead3
blablabla
blablabla
~/tmp$ < inputfile perl -0777 -pe 's/.*[*]{3}\n(.*\n)\n.*/$1/s'
thingsIwantToRead1
thingsIwantToRead2
thingsIwantToRead3
~/tmp$
Related videos on Youtube
 20 : 02
20 : 02
 08 : 32
08 : 32
 06 : 26
06 : 26
 04 : 14
04 : 14
 25 : 45
25 : 45
 06 : 27
06 : 27
JoVe
Updated on September 18, 2022Comments
-
JoVe over 1 year
I have a file like below:
blablabla blablabla *** thingsIwantToRead1 thingsIwantToRead2 thingsIwantToRead3 blablabla blablablaI want to extract the paragraph with
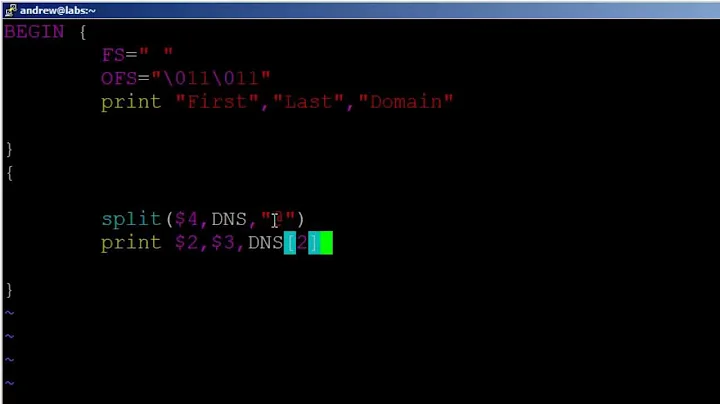
thingsIwantToRead. When I had to deal with such a problem, I used AWK like this:awk 'BEGIN{ FS="Separator above the paragraph"; RS="" } {print $2}' $file.txt | awk 'BEGIN{ FS="separator below the paragraph"; RS="" } {print $1}'And it worked.
In this case, I tried to put
FS="***","\*{3}","\*\*"(it is not working because AWK treats it like a normal asterisk),"\\*\\*"or whatever regex I could think of, but it's not working (it's printing nothing).Do you know why?
If not, do you know another way to deal with my problem?
Below an extract of the file I want to parse:
13.2000000000 , 3*0.00000000000 , 11.6500000000 , 3*0.00000000000 , 17.8800000000 Blablabla SATELLITE EPHEMERIS =================== Output frame: Mean of J2000 Epoch A E I RA AofP TA Flight Ang ***************************************************************************************************************** 2012/10/01 00:00:00.000 6998.239 0.001233 97.95558 77.41733 89.98551 290.75808 359.93398 2012/10/01 00:05:00.000 6993.163 0.001168 97.95869 77.41920 124.72698 274.57362 359.93327 2012/10/01 00:10:00.000 6987.347 0.001004 97.96219 77.42327 170.94020 246.92395 359.94706 2012/10/01 00:15:00.000 6983.173 0.000893 97.96468 77.42930 224.76158 211.67042 359.97311 <np> ---------------- Predicted Orbit: ---------------- BlablablaAnd I want to extract:
2012/10/01 00:00:00.000 6998.239 0.001233 97.95558 77.41733 89.98551 290.75808 359.93398 2012/10/01 00:05:00.000 6993.163 0.001168 97.95869 77.41920 124.72698 274.57362 359.93327 2012/10/01 00:10:00.000 6987.347 0.001004 97.96219 77.42327 170.94020 246.92395 359.94706 2012/10/01 00:15:00.000 6983.173 0.000893 97.96468 77.42930 224.76158 211.67042 359.97311And the command I tried to use to get the numbers after the line of *'s:
`awk 'BEGIN{ FS="\\*{2,}"; RS="" } {print $2}' file | awk 'BEGIN{ FS="<np>"; RS="" } {print $1}'`-
 terdon almost 9 yearsAre there
terdon almost 9 yearsAre there***after the target paragraph? -
JoVe almost 9 yearsNo. In the real file, there is a line containing <np> or ^L depending on the editor I use (nedit or vi), and I dont know what this means...
-
terdon almost 9 yearsSo, what part of the file do you want to extract? Are the slashes (at the beginning of the
*and--lines) actually part of the line? Do you want the data between****and<np>? Or until the next blank line? -
JoVe almost 9 yearsSorry no baskslashes, I added them when the text was not in a code block and forgot to remove them. Should be ok now, thanks.
-
JoVe almost 9 yearsThe file is generated by a routine I have no knowledge of, and depending on the editor I use there is either <np> (with nedit) or ^L (with vi, or less) after the paragraph I want to extract (the numbers after the * line and before <np>), so I don't know how to deal with it......
-
 mikeserv almost 9 yearsWhat? So does a literal
mikeserv almost 9 yearsWhat? So does a literal<np>in the file you wish to edit delimit the end of the paragraph - or is it a blank line instead? If you don't know the answer to that question then you have asked the wrong question. You need to first ask: What the hell is <np> anyway? -
JoVe almost 9 yearsThe first problem I encountered was the **** line. The <np> comes after. I don't think it's a literal <np>, it must mean something else.
-
terdon almost 9 years@JoVe please show us your desired output. It really isn't clear from your description. Make sure to put it in a code block.
-
terdon almost 9 yearsOK, see updated answer.
-
 kos almost 9 yearsHow many paragraphs (or
kos almost 9 yearsHow many paragraphs (or***separated sections) are are we expected to expect to be in your output? -
kos almost 9 yearsAlso, are
***separated sections always terminated by a<np>line? -
JoVe almost 9 yearsThere is only one paragraph to extract, the one between the line of *'s and the
<np>line (special character I dont know the meaning of). But I need to parse different files of the same type as the file I put as an example.
-
-
terdon almost 9 years@mikeserv because the title states "paragraph separated by
***" and because the output only shows the first set of lines. Since the OP refers to it as "the paragraph after***", I assumed that the***was between each paragraph. If that's not the case, the OP can use fredtantini's very good answer. -
JoVe almost 9 yearsThe way I was doing it, I treated the entire file as one record (hence the RS=""), and I used FS to read the paragraph I want (read as a field by awk). It worked until I had to deal with a "******" separator. Do you know why ? Even when I double escape the * it's not working. Your solution looks quicker though : can you explain how is it working ? I am not familiar with the -vRS option.
-
terdon almost 9 years@JoVe the
-vlets you set a variable. For exampleawk -v g="foo" 'BEGIN{print g}will returnfoosince that's the value of the variableg. I just wrote it with no space and used it to set theRSvariable. What******? I don't see that in your example. If you show us the actual file you are trying to parse (including this problematic******), I can update my answer. -
JoVe almost 9 yearsI edited my post : I put an extract of the file and an example of the awk command I used.
-
terdon almost 9 years@JoVe please use the formatting tools to format your post. Just paste it directly into your question, select it and then hit the
{}button. -
terdon almost 9 years@mikeserv why? To avoid the quoting issues?
-
mikeserv almost 9 yearsIt's mostly a hunch, actually, but this is all I know about it. I dunno if
awkdoes anything with*as it does for\t, really. But according to thatENVIRONis one of only two ways to hand it string literals. -
JoVe almost 9 yearsThanks for the edited answer, but there are still a few problems left.
awk '/\*{4,}/,/<np>/' fileis not working butawk '/\*\*\*\*/,/<np>/' fileworks, why ? <np> seems to be a special character, it is not recognized by awk. But I can parse until "Predicted orbit" and remove the last 3 lines. -
mikeserv almost 9 yearsBy the way - the
tail|headthing doesn't work for anything but the first paragraph - it still prints***\n.*\n<np>for all but the first paragraph. -
terdon almost 9 years@JoVe huh? What is
<np>? Is that an actual<,n,pand>or is it supposed to represent something else? There's nothing special about it. It's possible that yourawkflavor/version doesn't support{N,}but I can't know since you haven't told us anything about it. What OS are you on? -
JoVe almost 9 years@mikeserv I'm a beginner in all this, so instead of reacting like that, tell me what is stupid in my question so I can learn. In my beginner's head, \*{4,} not working can happen because of 2 things: either it does not recognize * (so I tested it to be sure it recognizes it) or {4,} is not working and I find it strange. How is that stupid ?? Anyway it's not important. To Terdon: Well it's not a <, n, p and >, it is supposed to represent something else but I dont know what. Again, it's not important. Sorry to have wasted your time and thank you for your help !
-
JoVe almost 9 years@mikeserv Yes I understand. I'll do better next time. ;) I've get round the problem of <np> by doing this:
'/\*\*/ {parse=1; next} /^[^2]/ {parse=0} parse==1 {print}' file. Thanks again ! -
terdon almost 9 years@JoVe OK, so, presumably, your
<np>is actually "lines that don't begin with a2" (that's what you're matching, anyway). Could you please accept one of the answers by clicking on the check mark to the left? That will mark the question as answered and is the way thanks are expressed on the Stack Exchange sites. -
mikeserv almost 9 yearsDoes this handle the sample data provided?
-
kos almost 9 years@mikeserv Yes, I've added a sample output of the command
-
mikeserv almost 9 yearsHmmm... That doesn't look like the sample I see... Oh, I guess it is still here in the question. The op edited to provide a more accurately representative sample. Have you tried it there?
-
kos almost 9 years@mikeserv No I didn't, I actually didn't even notice that the question was updated (I have left this open for a while before answering). It won't work on the updated input file, so I'm editing it accordingly, thanks
-
mikeserv almost 9 yearsIs the
\n(.*)greedy? Will it not edit out all but the last occurrence of a matching paragraph? Or, I guess that should be, will it include everything between paragraph 1 and 2 if there are two possible matches for*[*]*\n(.*)\n<np>? -
kos almost 9 years@mikeserv Hm, I'm having troubles understanding. It will match only the last occurence of the target pattern if there are multiple possible matches. This however doesn't seem to be likely to happen, at least judging from the sample input
-
mikeserv almost 9 yearsYeah - I'm unclear on that too - the question just really did a 180. I guess I'm still holding onto my initial impression from first reading it - which was how to print only a paragraph in a file following a unique marker. I ask though because it looks like
*[*]\nmatches the first occurrence of that string in input and(.*)matches everything up to the last\n<np>. And so if there were two - would it not getparagraph1 <np> middle junk \*\*\* paragraph2? I'm useless with w/perlby the way, and so I really honestly curious. -
kos almost 9 years@mikeserv Perl is greedy by default, and in my experience specifying an exact pattern after a greedy pattern (say
.*) will match until the last occurence of the specified pattern and continue matching from there, so in this case the.*at the start itself will match until the last occurence of[*]+\n, in fact it will only print the last*separated section, and(.*)will match until the last occurence of<np>\n, which is (presumably) going to be only one per each*separated section -
kos almost 9 years@mikeserv However I asked OP about this also
-
mikeserv almost 9 yearsOh, yeah - i didn't notice the leading
.*- so, yeah, that squeezes it down to the last match.