How to define max_queue_size, workers and use_multiprocessing in keras fit_generator()?
Q_0:
Question: Does this refer to how many batches are prepared on CPU? How is it related to workers? How to define it optimally?
From the link you posted, you can learn that your CPU keeps creating batches until the queue is at the maximum queue size or reaches the stop. You want to have batches ready for your GPU to "take" so that the GPU doesn't have to wait for the CPU. An ideal value for the queue size would be to make it large enough that your GPU is always running near the maximum and never has to wait for the CPU to prepare new batches.
Q_1:
Question: How do I find out how many batches my CPU can/should generate in parallel?
If you see that your GPU is idling and waiting for batches, try to increase the amount of workers and perhaps also the queue size.
Q_2:
Do I have to set this parameter to true if I change workers? Does it relate to CPU usage?
Here is a practical analysis of what happens when you set it to True or False. Here is a recommendation to set it to False to prevent freezing (in my setup True works fine without freezing). Perhaps someone else can increase our understanding of the topic.
In summary:
Try not to have a sequential setup, try to enable the CPU to provide enough data for the GPU.
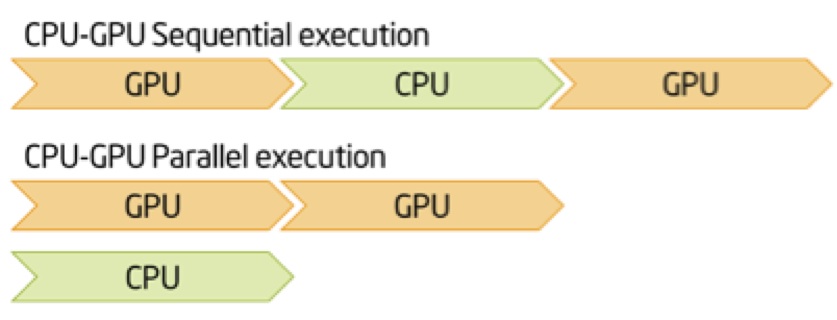
Also: You could (should?) create several questions the next time, so that it is easier to answer them.
Sophie Crommelinck
I am a PhD candidate at the ITC (University of Twente, Enschede, Netherlands). My PhD research is part of the H2020 project its4land of the European Union, which runs from February 2016 to January 2020. Within the project, I am responsible for one work package that aims to facilitate current land rights mapping procedures in Africa by extracting visible cadastral boundaries from remote sensing data. In my PhD, I have developed a boundary delineation tool that combines image analysis, machine learning, and GIS functionalities.
Updated on July 05, 2022Comments
-
 Sophie Crommelinck almost 2 years
Sophie Crommelinck almost 2 yearsI am applying transfer-learning on a pre-trained network using the GPU version of keras. I don't understand how to define the parameters
max_queue_size,workers, anduse_multiprocessing. If I change these parameters (primarily to speed-up learning), I am unsure whether all data is still seen per epoch.max_queue_size:maximum size of the internal training queue which is used to "precache" samples from the generator
Question: Does this refer to how many batches are prepared on CPU? How is it related to
workers? How to define it optimally?
workers:number of threads generating batches in parallel. Batches are computed in parallel on the CPU and passed on the fly onto the GPU for neural network computations
Question: How do I find out how many batches my CPU can/should generate in parallel?
use_multiprocessing:whether to use process-based threading
Question: Do I have to set this parameter to true if I change
workers? Does it relate to CPU usage?
Related questions can be found here:
- Detailed explanation of model.fit_generator() parameters: queue size, workers and use_multiprocessing
What is the parameter “max_q_size” used for in “model.fit_generator”?
A detailed example of how to use data generators with Keras.
I am using
fit_generator()as follows:history = model.fit_generator(generator=trainGenerator, steps_per_epoch=trainGenerator.samples//nBatches, # total number of steps (batches of samples) epochs=nEpochs, # number of epochs to train the model verbose=2, # verbosity mode. 0 = silent, 1 = progress bar, 2 = one line per epoch callbacks=callback, # keras.callbacks.Callback instances to apply during training validation_data=valGenerator, # generator or tuple on which to evaluate the loss and any model metrics at the end of each epoch validation_steps= valGenerator.samples//nBatches, # number of steps (batches of samples) to yield from validation_data generator before stopping at the end of every epoch class_weight=classWeights, # optional dictionary mapping class indices (integers) to a weight (float) value, used for weighting the loss function max_queue_size=10, # maximum size for the generator queue workers=1, # maximum number of processes to spin up when using process-based threading use_multiprocessing=False, # whether to use process-based threading shuffle=True, # whether to shuffle the order of the batches at the beginning of each epoch initial_epoch=0)The specs of my machine are:
CPU : 2xXeon E5-2260 2.6 GHz Cores: 10 Graphic card: Titan X, Maxwell, GM200 RAM: 128 GB HDD: 4TB SSD: 512 GB -
boomkin almost 5 yearsVery helpful, but I don't agree that the question poster should ask these questions separately. These questions are related, which is exemplified by the fact that you made a one sentence summary at the end of your contribution.