Linux BTRFS - convert to single with failed drive
Solution 1
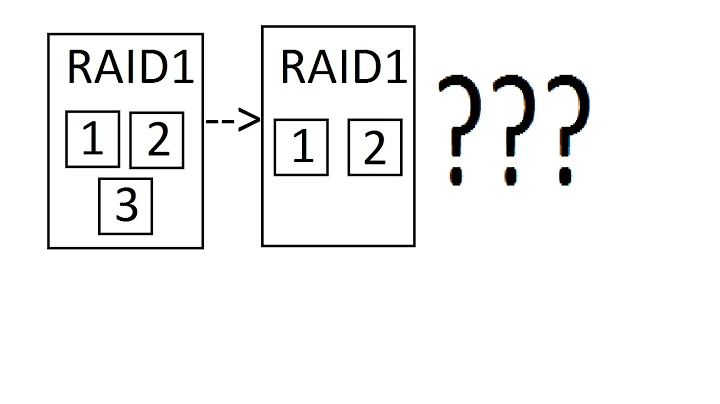
Alright, I figured it out with the help of this Trello link. In case anyone else wants to do this, here's the procedure.
Procedure
From a RAID1 array of two disks, one /dev/sda which is faulty and another /dev/sdc known-good:
- Disable auto-mounting of this array in
/etc/fstab, reboot. Basically, we want btrfs to forget this array exists, as there's a bug where it'll still try to use one of the drives if it's unplugged. -
Now that your array is unmounted, execute:
echo 1 | sudo tee /sys/block/sda/device/deletereplacing
sdawith the faulty device name. This causes the disk to spin down (you should verify this in dmesg) and become inaccessible to the kernel.Alternatively: just take the drive out of the computer before booting! I chose not to opt for this method, as the above works fine for me.
- Mount your array, with
-o degradedmode. - Begin a rebalancing operation with
sudo btrfs balance start -f -mconvert=single -dconvert=single /mountpoint. This will reorganise the extents on the known-good drive, converting them tosingle(non-RAID). This will take almost a day to complete, depending on the speed of your drive and size of your array. (mine had ~700 GiB, and rebalanced at a rate of 1 1GiB chunk per minute) Luckily, this operation can be paused, and will keep the array online while it occurs. - Once this is done, you can issue
sudo btrfs device remove missing /mountpointto remove the 'missing' faulty device. - Begin a second rebalance with
sudo btrfs balance start -mconvert=dup /mountpointto restore metadata redundancy. This takes a few minutes on my system. - You're done! Your array is now
singlemode, with all redundancy removed. - Take your faulty drive outside, and beat it with a hammer.
Troubleshooting
-
Help, btrfs tried to write to my faulty disk, errored out, and forced it readonly!
- Did you follow step 1, and reboot before continuing? It's likely that btrfs still thinks the drive you spun down is present. Rebooting will cause btrfs to forget any errors, and will let you continue.
Solution 2
Thanks for your post. I had this idea that I could test out raid, pop the drive out of my hotswap bay, use another drive and and then pop the raid drive back in. In retrospect, this was a bad idea and now I need my hotswap bay.
Here's what I found. As root:
# sudo btrfs fi show
Label: 'disk' uuid: 12817aeb-d303-4815-8bba-a3440e36c62c
Total devices 2 FS bytes used 803.10GiB
devid 1 size 931.51GiB used 805.03GiB path /dev/sda1
devid 2 size 931.51GiB used 805.03GiB path /dev/sdb1
Note the devid listed for each drive. Man for brtrfs balance lead me to the devid option, took a couple tries to figure out how the filters worked (initially trying devid=/dev/sdb1). So your first attempt is going to look something like this.
# btrfs balance start -dconvert=single,devid=2 -mconvert=single,devid=2 /mnt
Which gave me an error.
ERROR: error during balancing '/media/.media': Invalid argument
There may be more info in syslog - try dmesg | tail
Here's the error from dmesg:
BTRFS error (device sdb1): balance will reduce metadata integrity, use force if you want this
So this is the final that worked:
# btrfs balance start -f -dconvert=single,devid=2 -mconvert=single,devid=2 /mnt
Hopefully this helps someone else out.
Related videos on Youtube
 08 : 02
08 : 02
 48 : 52
48 : 52
 15 : 34
15 : 34
 03 : 49
03 : 49
 06 : 56
06 : 56
 11 : 51
11 : 51
eeeeeta
Updated on September 18, 2022Comments
-
 eeeeeta almost 2 years
eeeeeta almost 2 yearsA small amount of backstory:
I have a small media filesystem, on which I store various movies and TV shows that are used for my HTPC setup. This was originally set up, using
btrfs, on a 1TB WD external drive.Later, I decided to purchase another drive, to give this filesystem RAID1 mirroring capabilities. This drive is a Seagate Barracuda (2TB, BARRACUDA 7200.14 FAMILY). Unfortunately, this was not a good choice of drive. The drive started developing large amounts of read errors shortly, although BTRFS was able to correct them.
Recently, the amount of read errors from this drive has spiked, with its condition steadily worsening. BTRFS is now starting to crash:
kernel: RSP: 0018:ffff88005f0e7cc0 EFLAGS: 00010282 kernel: RIP: 0010:[<ffffffffa0081736>] [<ffffffffa0081736>] btrfs_check_repairable+0xf6/0x100 [btrfs] kernel: task: ffff88001b5c4740 ti: ffff88005f0e4000 task.ti: ffff88005f0e4000 kernel: Workqueue: btrfs-endio btrfs_endio_helper [btrfs] kernel: CPU: 1 PID: 3136 Comm: kworker/u8:3 Tainted: G O 4.5.3-1-ARCH #1 kernel: invalid opcode: 0000 [#1] PREEMPT SMP kernel: kernel BUG at fs/btrfs/extent_io.c:2309! kernel: ------------[ cut here ]------------ kernel: BTRFS info (device sdc1): csum failed ino 73072 extent 1531717287936 csum 3335082470 wanted 3200325796 mirror 0 kernel: ata3: EH complete kernel: BTRFS error (device sdc1): bdev /dev/sda3 errs: wr 0, rd 18, flush 0, corrupt 0, gen 0 kernel: blk_update_request: I/O error, dev sda, sector 2991635296I'd like to remove the faulty drive from the RAID1 array, going back to no redundancy on a single drive. Unfortunately, there seems to be a lack of documentation on how to do this.
I am aware that one can run the following:
sudo btrfs balance start -dconvert=single /mediato convert the data profile to
singlemode, but I'm unsure as to just WHERE the data will be placed. As one of the drives is failing, I'd like to be able to ensure that BTRFS doesn't dutifully erase all the data on the good drive, and place a single copy on the bad drive - instead, I'd like to simply act as if the other drive never existed (as in, convert back to my old setup)This doesn't work:
$ sudo btrfs device delete /dev/sda3 /media ERROR: error removing device '/dev/sda3': unable to go below two devices on raid1What am I to do? Help would be greatly appreciated.
TL;DR: started with 1 drive in BTRFS
single, added another drive, made itRAID1, other drive is now erroring, how do I return to just one drive (SPECIFICALLY the known good one) withsingle? -
HelloSam over 7 yearsThis doesn't work. I am on Ubuntu 16.04 (Kernel 4.4). dmesg says "missing devices(1) exceeds the limit(0), writeable mount is not allowed". Thus I am stucked at the "mount -o degraded" step
-
jaltek over 7 years@HelloSam: Maybe this is bug. See bbs.archlinux.org/viewtopic.php?id=210541
-
dma_k about 7 yearsIf you wanted just to replace one drive with another, you could do it using
btrfs replace. -
YtvwlD over 5 yearsThis has worked for me a year ago or so, but doesn't today. It doesn't matter what I type after
devid=, the resulting single data is placed on device 1. -
 Tom Hale over 5 yearsAlso check out
Tom Hale over 5 yearsAlso check out-sconvertto convert system chunks. -
Tom Hale over 5 yearsConsider using
|instead of,as the man page for balance says:profiles=<profiles>Balances only block groups with the given profiles. Parameters are a list of profile names separated by "|" (pipe) -
Tom Hale over 5 yearsConsider adding
,softafter eachconvert=to skip chunks which already have the target profile (which should be all of them). -
mgutt over 3 yearsI'm getting "writable mount is not allowed due to too many missing devices"?
-
JinnKo over 3 yearsThis approach didn't do what I expected. The result is that the data is now distributed across the two devices, however with only a single copy. So if I remove the second device now I'll lose data :(