How to handle changing parquet schema in Apache Spark
Solution 1
As I read the data in daily chunks from JSON and write to Parquet in daily S3 folders, without specifying my own schema when reading JSON or converting error-prone columns to correct type before writing to Parquet, Spark may infer different schemas for different days worth of data depending on the values in the data instances and write Parquet files with conflicting schemas.
It may not be the perfect solution, but the only way I found to solve my problem with an evolving schema is the following:
Before my daily (more specifically nightly) cron job of batch processing previous day's data I am creating a dummy object with mostly empty values.
I make sure the ID is recognizable, for example as the real data has unique ID-s, I add "dummy" string as an ID to the dummy data object.
Then I will give expected values for properties with error-prone types, for example I will give floats/doubles non-zero values so when marshalling to JSON, they would definitely have decimal separator, for example "0.2" instead of "0" (When marshalling to JSON, doubles/floats with 0 values are shown as "0" not "0.0").
Strings and booleans and integers work fine, but in addition to doubles/floats I also needed to instantiate arrays as empty arrays and objects of other classes/structs with corresponding empty objects so they wouldn't be "null"-s, as Spark reads null-s in as strings.
Then if I have all the necessery fields filled, I will marshall the object to JSON and write the files to S3.
Then I would use these files in my Scala batch processing script to read them in, save the schema to a variable and give this schema as a parameter when I read in the real JSON data to avoid Spark doing its own schema inferring.
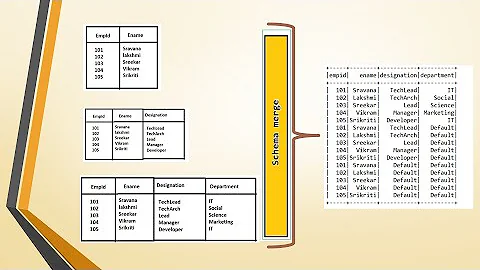
That way I know all the fields are always of the same type and schema merging is only necessary to join schemas when new fields are added.
Of course it adds a drawback of manually updating the dummy object creation when new fields of error-prone types are added, but this is currently a small drawback as it is the only solution I have found that works.
Solution 2
These are the options I use for writing parquet to S3; turning off schema merging boosts writeback performance -it may also address your problem
val PARQUET_OPTIONS = Map(
"spark.sql.parquet.mergeSchema" -> "false",
"spark.sql.parquet.filterPushdown" -> "true")
Solution 3
Just make an rdd[String] where each string is a json,when making the rdd as dataframe use primitiveAsString option to make all the datatypes to String
val binary_zip_RDD = sc.binaryFiles(batchHolder.get(i), minPartitions = 50000)
// rdd[String] each string is a json ,lowercased json
val TransformedRDD = binary_zip_RDD.flatMap(kv => ZipDecompressor.Zip_open_hybrid(kv._1, kv._2, proccessingtimestamp))
// now the schema of dataframe would be consolidate schema of all json strings
val jsonDataframe_stream = sparkSession.read.option("primitivesAsString", true).json(TransformedRDD)
println(jsonDataframe_stream.printSchema())
jsonDataframe_stream.write.mode(SaveMode.Append).partitionBy(GetConstantValue.DEVICEDATE).parquet(ApplicationProperties.OUTPUT_DIRECTORY)
Related videos on Youtube
 08 : 10
08 : 10
 08 : 45
08 : 45
 13 : 43
13 : 43
 04 : 29
04 : 29
 08 : 02
08 : 02
 08 : 00
08 : 00
 07 : 10
07 : 10
V. Samma
Updated on July 09, 2022Comments
-
V. Samma almost 2 years
I have run into a problem where I have Parquet data as daily chunks in S3 (in the form of
s3://bucketName/prefix/YYYY/MM/DD/) but I cannot read the data in AWS EMR Spark from different dates because some column types do not match and I get one of many exceptions, for example:java.lang.ClassCastException: optional binary element (UTF8) is not a groupappears when in some files there's an array type which has a value but the same column may have
nullvalue in other files which are then inferred as String types.or
org.apache.spark.SparkException: Job aborted due to stage failure: Task 23 in stage 42.0 failed 4 times, most recent failure: Lost task 23.3 in stage 42.0 (TID 2189, ip-172-31-9-27.eu-west-1.compute.internal): org.apache.spark.SparkException: Failed to merge incompatible data types ArrayType(StructType(StructField(Id,LongType,true), StructField(Name,StringType,true), StructField(Type,StringType,true)),true)I have raw data in S3 in JSON format and my initial plan was to create an automatic job, which starts an EMR cluster, reads in the JSON data for the previous date and simply writes it as parquet back to S3.
The JSON data is also divided into dates, i.e. keys have date prefixes. Reading JSON works fine. Schema is inferred from the data no matter how much data is currently being read.
But the problem rises when parquet files are written. As I understand, when I write parquet with metadata files, these files contain the schema for all parts/partitions of the parquet files. Which, to me it seems, can also be with different schemas. When I disable writing metadata, Spark was said to infer the whole schema from the first file within the given Parquet path and presume it stays the same through other files.
When some columns, which should be
doubletype, have only integer values for a given day, reading in them from JSON (which has these numbers as integers, without floating points) makes Spark think it is a column with typelong. Even if I can cast these columns to double before writing the Parquet files, this still is not good as the schema might change, new columns can be added, and tracking this is impossible.I have seen some people have the same problems but I have yet to find a good enough solution.
What are the best practices or solutions for this?
-
V. Samma over 7 yearsHi, I will try this out. But I was wondering, do you include this
PARQUET_OPTIONSmap in the.option()function while writing parquet? But how about reading? I only usedsqlContext.read.option("mergeSchema", true).parquet("path"), but still used regular write without options. -
V. Samma over 7 yearsWell, I tried both read and write with
.option("mergeSchema", "false").option("filterPushdown","true")and it didn't change a thing. When mergeSchema is true, I getFailed to merge incompatible data types DoubleType and LongTypeand when it's false, reading the data works. Printing schema shows the column is of double type andshow()command shows 20 first lines, but filtering and grouping on that column fails:Cost's declared type (java.lang.Double) does not match the schema found in file metadata. -
 stevel over 7 yearssounds like some of your files have inconsistent schemas
stevel over 7 yearssounds like some of your files have inconsistent schemas -
V. Samma over 7 yearsWell, that what I was trying to say in my initial question. I have two problems. Firstly, if an expected double column has only integer values, spark reads it in as "long" and not "double". Then writing that data to parquet for maybe two different days may result a single column being "double" for one day and "long" for the other day. I want spark to understand that both should be double. OR the second problem is with arrays. If a column should have arrays, but for one day this specific column does not have values, spark thinks of it as a string type and then it can't fit one schema to both.
-
stevel over 7 yearsafraid you are into the depths or Parquet I'm afraid; not my area of expertise. I think you need to be rigorous about defining your schema up front, and declaring the long as long, the array as array, etc. That way, every file will have a consistent schema and there's no merge problem.
-
V. Samma over 7 yearsYeah but I cannot define the schema in Spark manually because our data has more than 200 fields and as we develop our system, the structure changes a lot. A lot of columns are added, some may be removed, it would be impossible to keep this schema synchronized and up to date in Spark. I wonder if this problems only occurs when column types mismatch but merging works when some files have just more columns for example. Or whether it is possible to define the types of some columns and let spark infer the others.
-
stevel over 7 yearsSlack have recently posted on this topic. A key theme of theirs is "never remove fields, only add them at the end". After all, if you mark a field is optional, you can omit the data. Like I said, this isn't an area I work in. What I do know is that schema merging requires parquet to read the schema at the end of every single file, which is expensive, especially on Hadoop < 2.8, where seeking on s3a is expensive. If you have to do the merge, you have to take the hit. Sorry
-
V. Samma over 7 yearsYes, currently merge doesn't help as it is not able to select one type and use it. Only thing it does, is throw an exception while reading that the schema doesn't match. Without it we get an error later while doing groupBy's or something like that. We have data structures in our GoLang servers and these end up in S3 as JSON files. Adding new fields is the most common option (but not at the end, because some fields can be added in nested structs etc), but I think some may be removed as well. Types are probably not changed, but if data is missing, spark does interpret the type differently
-
Sim about 7 yearsHow this is better than custom parsing the data during Spark processing, i.e., reading strings, parsing with
json4sand building the case classes you need? -
V. Samma about 7 years@Sim Good question. I wanted to automate the solution as much as possible. As the schema is evolving almost every day, building case classes is not efficient. The raw data structures are defined in Go applications and involve at least 200-300 or more data attributes. When adding a new one to the original structure, a new field should be added to the case class as well. But if this is done by different people, it is quite impossible to keep track of and maintain.
-
 Avishek Bhattacharya over 6 yearsI couldn't able to understand how are you writing the data to s3. Are you doing rdd union with the dummy object and the incoming data and store that ?
Avishek Bhattacharya over 6 yearsI couldn't able to understand how are you writing the data to s3. Are you doing rdd union with the dummy object and the incoming data and store that ? -
V. Samma over 6 years@Avishek My real data came through Firehose and was stored in S3. My dummy data was just written/uploaded to S3 in another location. Then while reading all the data, I included the path of the dummy file together with the paths of real data. Then I just had one line of dummy data which gave the whole dataset the correct schema. Later I just had to filter it out or remove some other way.
-
Avishek Bhattacharya over 6 yearsYes that makes lot of sense, However if the incoming data has incompatible types, like you have string in the dummy item and incoming data has Array[String] and if the dummy hasn't been updated the merge schema will fail. Do you do sanity check on the incoming data schema ?
-
V. Samma over 6 years@Avishek My solution was meant for the reason to fix the incompatible types problem. Our data types were defined in Go structures. So up-to-date dummy data had strings only where there were string type properties, for arrays, the dummy data had predefined dummy arrays. So the real data may have had string values and array values for actual array type, but not array value for a property with string type. Actually only option was that a new array type property was added to the structure but not the correct value for the dummy object, then it would have failed yes, there were no checks for that.
-
Programmer over 6 yearsI am facing the exact same issue. May I know how you solved it for existing data on s3? Were you able to read it and process it?
-
V. Samma over 6 years@JaspinderVirdee Well, I had this problem during the development phase and wasn't really concerned about past data. But it's basically the same, you can go through the old data and read it together with the dummy data which has the correct latest data schema. If you have added fields only, it should work. If you have changed data types for some fields then you need to make sure old data can be read in as the new data type. For example if you have changed an int to float or something like that. But this solution worked for raw data like JSON, which schema is inferred without metadata.