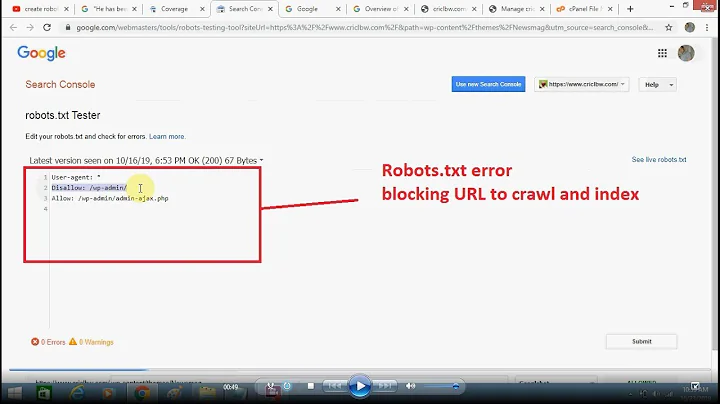
robots.txt: user-agent: Googlebot disallow: / Google still indexing
Solution 1
Besides having to wait, because Google's index updates take some time, also note that if you have other sites linking to your site, robots.txt alone won't be sufficient to remove your site.
Quoting Google's support page "Remove a page or site from Google's search results":
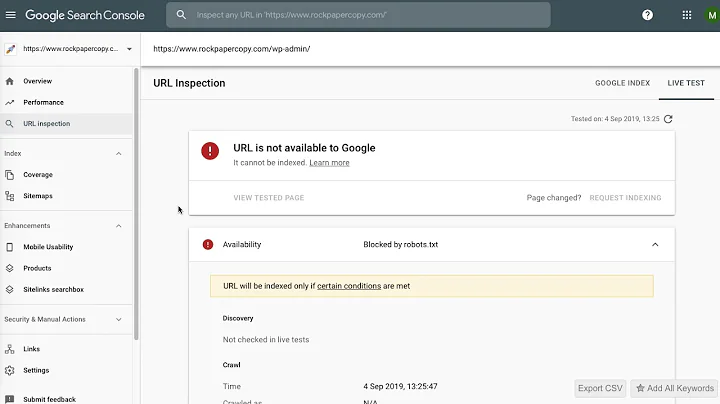
If the page still exists but you don't want it to appear in search results, use robots.txt to prevent Google from crawling it. Note that in general, even if a URL is disallowed by robots.txt we may still index the page if we find its URL on another site. However, Google won't index the page if it's blocked in robots.txt and there's an active removal request for the page.
One possible alternative solution is also mentioned in above document:
Alternatively, you can use a noindex meta tag. When we see this tag on a page, Google will completely drop the page from our search results, even if other pages link to it. This is a good solution if you don't have direct access to the site server. (You will need to be able to edit the HTML source of the page).
Solution 2
If you just added this, then you'll have to wait - it's not instantaenous - until Googlebot comes back to respider the site and sees the robots.txt, the site'll still be in their database.
I doubt it's relevant, but you might want to change your "Agent" to "agent" - Google's most likely not case sensitive for this, but can't hurt to follow the standard exactly.
Solution 3
I can confirm Google doesn't respect the Robots Exclusion File. Here's my file, which I created before putting this origin online:
https://git.habd.as/robots.txt
And the full contents of the file:
User-agent: *
Disallow:
User-agent: Google
Disallow: /
And Google still indexed it.
I don't use Google after cancelling my account last March and never had this site added to a webmaster console outside Yandex which leaves me with two assumptions:
- Google is scraping Yandex
- Google doesn't respect the Robots Exclusion Standard
I haven't grepped my logs yet but I will and my assumption is I'll find Google spiders in there misbehaving.
Related videos on Youtube
 04 : 21
04 : 21
 04 : 46
04 : 46
 10 : 54
10 : 54
 01 : 20
01 : 20
 11 : 21
11 : 21
 06 : 56
06 : 56
 12 : 47
12 : 47
 06 : 12
06 : 12
 06 : 36
06 : 36
 05 : 00
05 : 00
 05 : 26
05 : 26
Comments
-
Anders almost 2 years
Look at the robots.txt of this site:
The content is:
User-Agent: Googlebot Disallow: /That ought to tell google not to index the site, no?
If true, why does the site appear in google searches?
-
user772401 over 13 yearsDid you use the Google Webmaster Tools to check your robots.txt file?
-
-
Anders over 13 yearsThanks. But the file has been there since 2008 so it should have taken effect by now ;) Could the capitalized "Agent" be the reason why google doesnt respect it?
-
Jim Mischel over 13 yearsYou might want to emphasize the last part of the first quote: "...and there's an active removal request for the page."
-
Marc B over 13 yearsWon't hurt to change it. And then just wait for googlebot to show up again. If the only hit it makes on your site is robots txt, you'll know the change worked.
-
 vhs over 5 yearsIsn't this in reference to sites already indexed? Forcing one into Google's walled garden of tools is scantly a way for Google to respect the Exclusion Standard.
vhs over 5 yearsIsn't this in reference to sites already indexed? Forcing one into Google's walled garden of tools is scantly a way for Google to respect the Exclusion Standard.