What is the significance of load factor in HashMap?
Solution 1
The documentation explains it pretty well:
An instance of HashMap has two parameters that affect its performance: initial capacity and load factor. The capacity is the number of buckets in the hash table, and the initial capacity is simply the capacity at the time the hash table is created. The load factor is a measure of how full the hash table is allowed to get before its capacity is automatically increased. When the number of entries in the hash table exceeds the product of the load factor and the current capacity, the hash table is rehashed (that is, internal data structures are rebuilt) so that the hash table has approximately twice the number of buckets.
As a general rule, the default load factor (.75) offers a good tradeoff between time and space costs. Higher values decrease the space overhead but increase the lookup cost (reflected in most of the operations of the HashMap class, including get and put). The expected number of entries in the map and its load factor should be taken into account when setting its initial capacity, so as to minimize the number of rehash operations. If the initial capacity is greater than the maximum number of entries divided by the load factor, no rehash operations will ever occur.
As with all performance optimizations, it is a good idea to avoid optimizing things prematurely (i.e. without hard data on where the bottlenecks are).
Solution 2
Default initial capacity of the HashMap takes is 16 and load factor is 0.75f (i.e 75% of current map size). The load factor represents at what level the HashMap capacity should be doubled.
For example product of capacity and load factor as 16 * 0.75 = 12. This represents that after storing the 12th key – value pair into the HashMap , its capacity becomes 32.
Solution 3
Actually, from my calculations, the "perfect" load factor is closer to log 2 (~ 0.7). Although any load factor less than this will yield better performance. I think that .75 was probably pulled out of a hat.
Proof:
Chaining can be avoided and branch prediction exploited by predicting if a bucket is empty or not. A bucket is probably empty if the probability of it being empty exceeds .5.
Let s represent the size and n the number of keys added. Using the binomial theorem, the probability of a bucket being empty is:
P(0) = C(n, 0) * (1/s)^0 * (1 - 1/s)^(n - 0)
Thus, a bucket is probably empty if there are less than
log(2)/log(s/(s - 1)) keys
As s reaches infinity and if the number of keys added is such that P(0) = .5, then n/s approaches log(2) rapidly:
lim (log(2)/log(s/(s - 1)))/s as s -> infinity = log(2) ~ 0.693...
Solution 4
What is load factor ?
The amount of capacity which is to be exhausted for the HashMap to increase its capacity.
Why load factor ?
Load factor is by default 0.75 of the initial capacity (16) therefore 25% of the buckets will be free before there is an increase in the capacity & this makes many new buckets with new hashcodes pointing to them to exist just after the increase in the number of buckets.
Why should you keep many free buckets & what is the impact of keeping free buckets on the performance ?
If you set the loading factor to say 1.0 then something very interesting might happen.
Say you are adding an object x to your hashmap whose hashCode is 888 & in your hashmap the bucket representing the hashcode is free , so the object x gets added to the bucket, but now again say if you are adding another object y whose hashCode is also 888 then your object y will get added for sure BUT at the end of the bucket (because the buckets are nothing but linkedList implementation storing key,value & next) now this has a performance impact ! Since your object y is no longer present in the head of the bucket if you perform a lookup the time taken is not going to be O(1) this time it depends on how many items are there in the same bucket. This is called hash collision by the way & this even happens when your loading factor is less than 1.
Correlation between performance, hash collision & loading factor
- Lower load factor = more free buckets = less chances of collision = high performance = high space requirement.
- Higher load factor = fewer free buckets = higher chance of collision = lower performance = lower space requirement.
Solution 5
From the documentation:
The load factor is a measure of how full the hash table is allowed to get before its capacity is automatically increased
It really depends on your particular requirements, there's no "rule of thumb" for specifying an initial load factor.
Related videos on Youtube
 15 : 29
15 : 29
 03 : 11
03 : 11
 07 : 23
07 : 23
 02 : 40
02 : 40
 04 : 22
04 : 22
 08 : 50
08 : 50
 04 : 05
04 : 05
 01 : 41
01 : 41
 18 : 47
18 : 47
Priyank Doshi
I am a software development engineer at Amazon. Language: java c/c++ html , css , jquery Frameworks: Spring core & MVC Hibernate
Updated on March 11, 2022Comments
-
 Priyank Doshi over 2 years
Priyank Doshi over 2 yearsHashMaphas two important properties:sizeandload factor. I went through the Java documentation and it says0.75fis the initial load factor. But I can't find the actual use of it.Can someone describe what are the different scenarios where we need to set load factor and what are some sample ideal values for different cases?
-
blackr1234 almost 3 yearsJava has many different distributions and versions. This is a very old question but those who visit this post may be using newer Java versions. A very important point is that before Java 8,
HashMapisn't really well written. That's why the JDK developers rewriteHashMapin Java 8. -
blackr1234 almost 3 yearsIf you look at the source code of
HashMapin Oracle JDK 7, you can see that in theaddEntrymethod (called fromput(k, v)), theresizemethod will only be called when(size >= threshold) && (null != table[bucketIndex])which means that size has to reach the load factor (i.e.75%) of the capacity, AND, the current bucket has collision. Therefore, load factor is only part of the story in Oracle JDK 7. In Oracle JDK 8, the latter condition no longer exists.
-
-
 supermitch over 10 yearsOther answers are suggesting specify
supermitch over 10 yearsOther answers are suggesting specifycapacity = N/0.75to avoid rehashing, but my initial thought was just setload factor = 1. Would there be downsides to that approach? Why would load factor affectget()andput()operation costs? -
atimb over 10 yearsA load factor=1 hashmap with number of entries=capacity will statistically have significant amount of collisions (=when multiple keys are producing the same hash). When collision occurs the lookup time increases, as in one bucket there will be >1 matching entries, for which the key must be individually checked for equality. Some detailed math: preshing.com/20110504/hash-collision-probabilities
-
BrainSlugs83 over 9 yearsI'm not following you @atimb; The loadset property is only used to determine when to increase the storage size right? -- How would having a loadset of one increase the likelyhood of hash collisions? -- The hashing algorithm has no knowledge of how many items are in the map or how often it acquires new storage "buckets", etc. For any set of objects of the same size, regardless of how they are stored, you should have the same probability of repeated hash values...
-
30thh over 9 yearsThe probability of the hash collision is less, if the size of the map is bigger. For example elements with hash codes 4, 8, 16 and 32 will be placed in the same bucket, if the size of the map is 4, but every item will get an own bucket, if the size of the map is more than 32. The map with initial size 4 and load factor 1.0 (4 buckets, but all the 4 element in a single bucket) will be in this example in average two times slower than another one with the load factor 0.75 (8 buckets, two buckets filled - with element "4" and with elements "8", "16", "32").
-
user1122069 almost 8 yearsYou could add a bit about how the hashCode is stripped down to a number with the range of 1-{count bucket}, and so it is not per-se the number of buckets, but that end-result of the hash algorithm covers a larger range. HashCode is not the full hash algorithm, it is just small enough to be easily re-processed. So there is no concept of "free buckets", but "minimum number of free buckets", since you could be storing all your elements in the same bucket. Rather, it is the key-space of your hashcode, which is equal to capacity*(1/load_factor). 40 elements, 0.25 load factor = 160 buckets.
-
 userab about 7 yearsAlthough your answer is clear, can you please tell whether just after storing 12 key-value pair the capacity becomes 32 or is it that when 13th entry is added, at that time capacity changes and then the entry is inserted.
userab about 7 yearsAlthough your answer is clear, can you please tell whether just after storing 12 key-value pair the capacity becomes 32 or is it that when 13th entry is added, at that time capacity changes and then the entry is inserted. -
 Decoded about 7 yearsMath nerds FTW! Likely the
Decoded about 7 yearsMath nerds FTW! Likely the.75was rounded to the nearest easy to understand fraction tolog(2), and looks like less of a magic number. I'd love to see an update to the JDK default value, with said comment above its implementation :D -
ferekdoley almost 7 yearsThe documentation also says; "As a general rule, the default load factor (.75) offers a good tradeoff between time and space costs.". So for anyone who's unsure, the default is a good rule of thumb.
-
LoveMeow almost 7 yearsdoes that mean the number of buckets are increased by 2?
-
Raf about 6 yearsI think the lookup time for an object from the
LinkedListis referred to asAmortized Constant Execution Timeand denoted with a+asO(1)+ -
Adelin almost 6 yearswhy higher values " increase the lookup cost ", can you explain ?
-
 searchengine27 over 5 yearsI really want to like this answer, but I'm a JavaEE developer, which means math was never really my strong suit, so I understand very little of what you wrote lol
searchengine27 over 5 yearsI really want to like this answer, but I'm a JavaEE developer, which means math was never really my strong suit, so I understand very little of what you wrote lol -
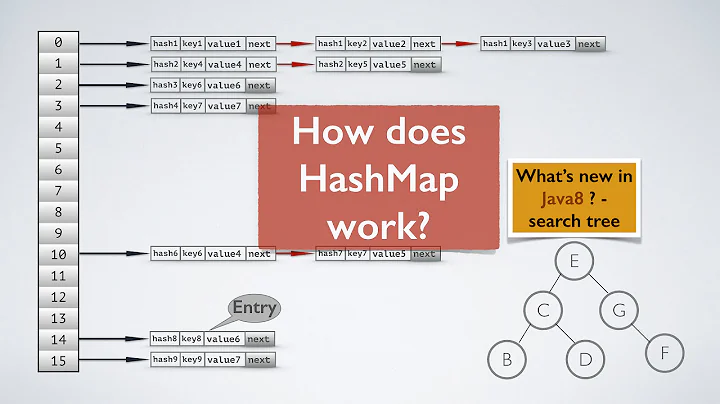
 Gigi Bayte 2 over 4 years@Adelin Lookup cost is increased for higher load factors because there will be more collisions for higher values, and the way that Java handles collisions is by putting the items with the same hashcode in the same bucket using a data structure. Starting in Java 8, this data structure is a binary search tree. This makes the lookup worst-case time complexity O(lg(n)) with the very worst case occurring if all of the elements added happen to have the same hashcode.
Gigi Bayte 2 over 4 years@Adelin Lookup cost is increased for higher load factors because there will be more collisions for higher values, and the way that Java handles collisions is by putting the items with the same hashcode in the same bucket using a data structure. Starting in Java 8, this data structure is a binary search tree. This makes the lookup worst-case time complexity O(lg(n)) with the very worst case occurring if all of the elements added happen to have the same hashcode. -
 ssynhtn almost 4 yearsThe premise that a bucket having the probability of 0.5 of fullness/emptyness would lead to optimal performance is simply unwarranted
ssynhtn almost 4 yearsThe premise that a bucket having the probability of 0.5 of fullness/emptyness would lead to optimal performance is simply unwarranted -
HelloWorld almost 4 years@ssynhtn Second sentence: Although any load factor less than this will yield better performance.
-
M. Prokhorov almost 4 years
.075may also be a good value that produces predictable integers when any power-of-two (above 1 and 2) integer is multiplied by it. It yields 3 for4 * LF, 6 for8 * LFand so on. -
user2846382 over 3 years@userab it will be on 13th entry, you might not be looking for that answer anymore but for others.
-
 Abhay Nagaraj almost 3 years@Adelin The lookup costs go high as they are directly proportional to the time we have, in order to increase the size of the hashtable's memory allocation when the threshold (LF*current capacity) is hit. As rehashing involves re-allocating contiguous memory locations to the entries and the fact that contiguous memory locations are not guaranteed to be available from currently allocated locations, makes it inevitable to perform move operations on each map entry, while it is being used to either put() into/get() from. If the LF is lower we get more time to reallocate before we hit the max limit.
Abhay Nagaraj almost 3 years@Adelin The lookup costs go high as they are directly proportional to the time we have, in order to increase the size of the hashtable's memory allocation when the threshold (LF*current capacity) is hit. As rehashing involves re-allocating contiguous memory locations to the entries and the fact that contiguous memory locations are not guaranteed to be available from currently allocated locations, makes it inevitable to perform move operations on each map entry, while it is being used to either put() into/get() from. If the LF is lower we get more time to reallocate before we hit the max limit. -
blackr1234 almost 3 yearsIt should be the
13th entry when resizing takes place. However, this answer applies to Oracle JDK 8 but not Oracle JDK 7. In Oracle JDK 7, there are2criteria for resizing to takes place. First, size must be>=threshold (cap * load factor). Second, the current bucket must already have an entry, which implies a collision. Refer to Oracle JDK 7u80 source code:null != table[bucketIndex]in theaddEntrymethod. -
 Glenn Slayden over 2 years@M.Prokhorov Don't you mean
Glenn Slayden over 2 years@M.Prokhorov Don't you mean0.75? -
M. Prokhorov over 2 years@GlennSlayden, yes, that was likely a typo. But I no longer can change my comment.